机器学习--隐马尔可夫模型(二)
机器学习 | 隐马尔可夫模型(二)
上周我们了解了什么是隐马尔可夫模型,这周我们来看看有了隐马尔可夫模型之后,能用它来做什么。
1、给定一个确定的隐马尔科夫模型(参数\(\lambda = \lbrace A,B,\pi\rbrace\)确定)和观察序列\(O\),计算在该参数下观察序列的输出概率 。
概率计算,由于观测序列的产生于隐状态是相关的,所以需要从隐状态的转移概率入手,通过发射概率间接的转化到观察序列。一般情况下该观测序列对应的隐状态序列有多个,把所有隐状态可能的序列结合观察序列求概率,再求和。
2、学习问题,已知观察序列\(O\),估计模型参数\(\lambda = \lbrace A,B,\pi\rbrace\),使得在该模型下观测序列的概率最大。
学习问题,假设在不知道模型参数的情况下,而我们有大量的观察序列,那么这些大量的观察序列一定不是偶然是这样,而不是那样的。从概率的角度来讲,是这样,而不是那样的原因就是,是这样的概率大于是那样的概率。如果有大量的观察序列,那么其中必然隐藏了模型的信息。
3、预测问题,已知模型的参数\(\lambda = \lbrace A,B,\pi\rbrace\)和观察序列\(O\),求解一条使得该观测序列概率最大的隐状态序列 。这样概率计算类似,只需要求最大的即可。
对应以上三个问题,分别有三个算法求解对应的问题:
- 概率计算-前向后向算法
- 参数学习-最大似然估计(有监督),Baum-Walch(无监督)
- 预测-Viterbi算法
这周我们主要说明第一个问题,下周说明后两个问题。
一、概率计算(观察序列的概率)
给定一个确定的隐马尔科夫模型(参数\(\lambda = \lbrace A,B,\pi\rbrace\)确定)和观察序列\(O = \lbrace o_1,o_2,...,o_t,...o_T\rbrace\),计算在该参数下观察序列的输出概率 。最直接的方法是计算所有可能的概率,即:
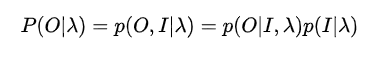
其中\(I = i_1,i_2,...,i_T\),这T个状态我们是看不见的,且每个时刻\(i_t\)的取值都有N种,由于隐状态与观察状态无关,其概率为:
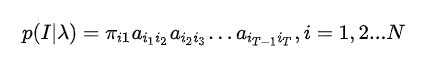
由于\(a_{ {i_t}{i_{t+1} } }\)的取值有\(N^2\)种,但序列前后有一个相同的状态,所以整个\(p(I|\lambda)\)的复杂度是\(TN^T\)。
而在参数和隐状态都确定的条件下,产生观察序列\(O = \lbrace o_1,o_2,...,o_t,...o_T\rbrace\)的概率为:
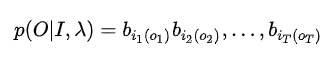
即整个T时刻的发射概率的乘积。
因此在给定参数的条件下,产生观察序列\(O = \lbrace o_1,o_2,...,o_t,...o_T\rbrace\)的概率为:
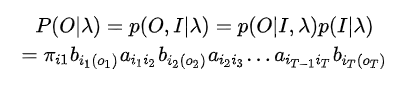
算法的复杂度为\(TN^T\)。之所以算法的复杂度高是分别计算\(a_{ {i_{t-1} }{i_{t} } }\)和\(a_{ {i_t}{i_{t+1} } }\),而忽略了序列之间的递推关系。
下面介绍隐马尔可夫概率计算问题中的前向-后向算法
前向概率:在给定模型的参数和观察序列\(O = \lbrace o_1,o_2,...,o_t\rbrace\)下,\(a_t(i)\)表示t时刻\(a_t = i\)的前向概率(从t = 1时刻到t时刻观察序列\(O = \lbrace o_1,o_2,...,o_t\rbrace,a_t = i\)):
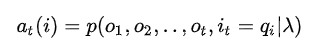
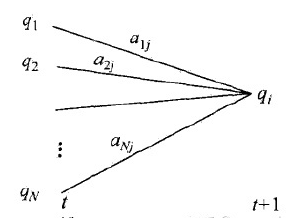
由前向递推关系\(a_t(i)\)等于在所有可能的前一状态转移到当前状态(同时t时刻发射出观测值\(o_t\))的概率之和:
因此前向算法计算如下:
- 初值:
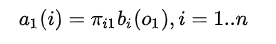
- 前向递推:

- 求和:
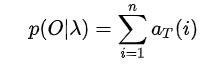
后向概率:在给定模型的参数和观察序列\(O = \lbrace o_{t+1}, o_{t+2},...,o_T\rbrace\)下,\(\beta_t(i)\)表示t时刻\(a_t = i\)的后向概率(从t时刻到T时刻观察序列\(O = \lbrace o_{t+1}, o_{t+2},...,o_T\rbrace,a_t=i\)):
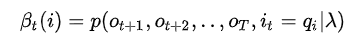
值得注意的是,后向概率表示序列从t时刻到T时刻的概率,所以\(\beta_t(i)\le\beta_{t+1}(j)\)
由后向递推关系\(\beta_t(i)\)等于所有可能的后一状态逆转移到当前状态(同时t+1时刻发射出观测值\(o_{t+1}\))的概率之和
因此后向算法计算如下:
1)初值:
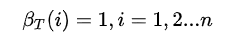
2)反向递推:
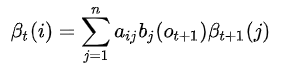
3)求和:
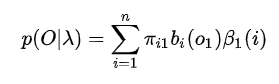
前向后向算法:
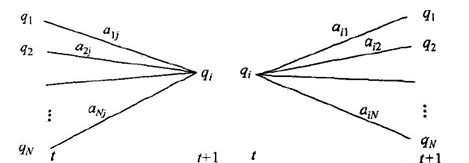
由上面的前向后向算法,固定t时刻的状态\(i_t = q_i\),由前向后向算法有:
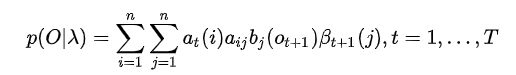
以上就是今天的内容,谢谢观看!