畅游人工智能之海--Keras教程之循环神经网络(一)
畅游人工智能之海--Keras教程之循环神经网络(一)
RNN是啥?
循环神经网络是具有内部存储器的前馈神经网络的概括。RNN本质上是递归的,因为它对数据的每个输入执行相同的操作,而当前输入的输出取决于过去的一次计算。产生输出后,将其复制并发送回循环网络。为了做出决定,它会考虑当前输入和从先前输入中学到的输出,具体的过程如图所示。 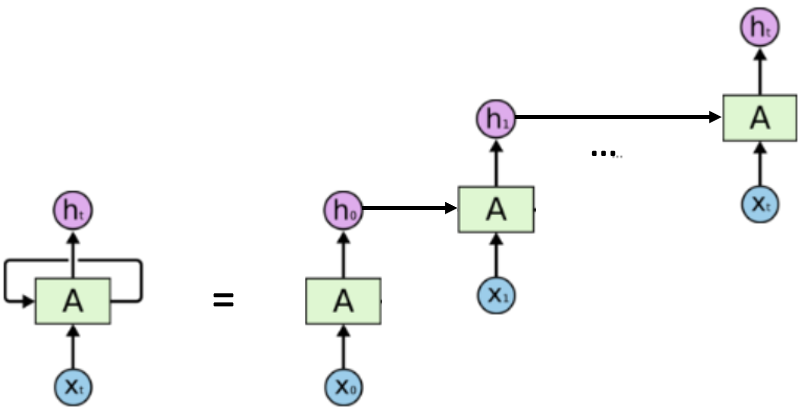 对应的计算公式可以表述为: \[
h_t = f(h_{t - 1},x_t)
\] 从计算公式中我们也能够看到,循环神经网络被开发的意义所在。一个具体的例子(加了激活函数和神经网络参数)就是: \[
h_t = tanh(W_{h} \cdot h_{t - 1} + W_x \cdot x_t)
\]
对应的计算公式可以表述为: \[
h_t = f(h_{t - 1},x_t)
\] 从计算公式中我们也能够看到,循环神经网络被开发的意义所在。一个具体的例子(加了激活函数和神经网络参数)就是: \[
h_t = tanh(W_{h} \cdot h_{t - 1} + W_x \cdot x_t)
\]
pros and cons
- RNN可以对数据序列进行建模,因此可以假定每个样本都依赖于先前的样本
- 循环多了长期的知识就循环没了(梯度消失)
keras 实现
SimpleRNN
1 | keras.layers.SimpleRNN(units, activation='tanh', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False) |
units:输出维度。
dropout: dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,如图所示。在这里就是一个概率值,取值[0,1]。
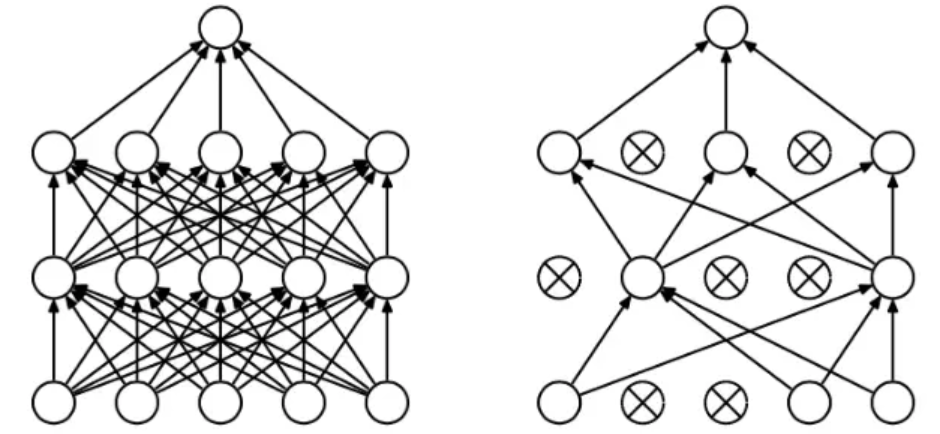 摘自https://www.jianshu.com/p/b5e93fa01385
摘自https://www.jianshu.com/p/b5e93fa01385
recurrent_drop:同理,因为这里有两个输入所以就有两个dropout。 return_sequences: 是返回输出序列中的最后一个输出(False)还是完整序列(True)。 return_state: 除输出外,是否返回最后一个状态。 go_backwards:如果为True,则向后处理输入序列,并返回相反的序列。 stateful:如果为True,则将批次中索引为 i 的每个样本的最后状态用作下一个批次中索引为 i 的样本的初始状态。 unroll:如果为True,则将展开网络,否则将使用符号循环。 展开可以加快RNN的速度,尽管它往往会占用更多的内存。 展开仅适用于短序列。
SimpleRNN‘s example
1 | from keras.layers import SimpleRNN |
直接运行结果
1 | _________________________________________________________________ |
about return_sequences
1 | layer = SimpleRNN(3,use_bias=False,return_sequences=True) |
1 | layer = SimpleRNN(3,use_bias=False,return_sequences=False) |
about return_state
1 | return_state=False: |