畅游人工智能之海--Keras教程之标准化层
畅游人工智能之海--Keras教程之标准化层
各位读者大家好,今天我们要一起来学习Keras的标准化层。首先,我会通过图解为大家讲解一下标准化层都做了什么,之后再为大家展示Keras中的标准化层函数。那接下来就让我们开始今天的学习吧!
Keras中的标准化层实际上就是批量标准化。它与普通的数据标准化类似,将分散的数据进行统一,有利于网络对于数据之中规律的学习。
我们先来看看数据标准化的必要性。
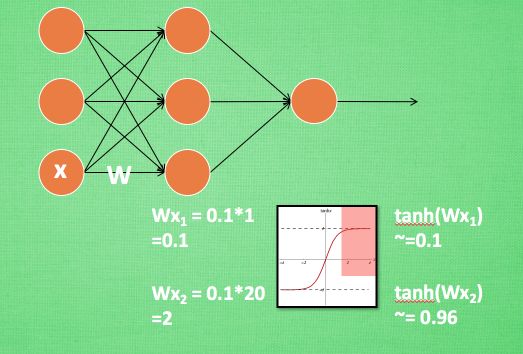
从图中可以看出,在神经网络中,当我们使用像tanh这样的激活函数之后,如果Wx的激活值在激励函数的饱和阶段时(如图中的红色部分所示),那么一个极大的值和一个较小的值经过激活函数处理之后的差别不大,即神经网络对较大的x特征范围不再敏感。这是很不好的事情,就像一个人已经无法感受到轻轻的拍打和重重一拳的区别了,这意味着感受能力大大降低。所以批标准化应运而生,来解决这件可怕的事情。它会对输入进行处理,使得数据进入激励函数的敏感部分,加强网络的学习能力。
一般批标准化层添加在每一个全连接和激励函数之间,对全连接层的计算结果经过标准化处理再经过激励函数处理。
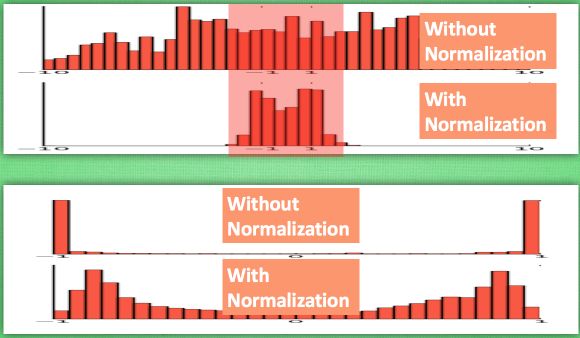
计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 标准化, 下者进行了 标准化, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程。
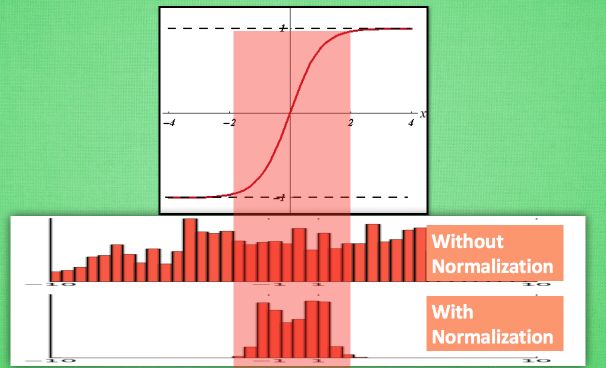
由下图可以看出,没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值。Keras的标准化层不仅会标准化数据,还会反标准化数据。
BatchNormalization
1 | keras.layers.BatchNormalization( |
作用:
批量标准化,在每一个批次的数据中标准化前一层的激活项, 即应用一个维持激活项平均值接近 0,标准差接近 1 的转换。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层,则需要指定 input_shape参数(整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同
相信大家经过今天的学习,能够对标准化层的功能有一个清晰的认知,标准化层是非常重要的网络层,它可以用于改善人工神经网络的性能和稳定性,使机器学习更容易学习到数据之中的规律。 所以希望各位能亲手实践以对它有更好地认识,大家一起加油!