畅游人工智能之海--Keras教程之概率损失函数篇
上周,我们一起学习了概率loss和回归loss中的class,今天我们便要完成接下来的内容:概率loss的function部分。
binary_crossentropy 函数
1
2
3
4
5
6
| tf.keras.losses.binary_crossentropy(
y_true,
y_pred,
from_logits=False,
label_smoothing=0
)
|
作用:
计算二分类任务交叉熵损失。
二分类任务交叉熵损失函数如下所示:
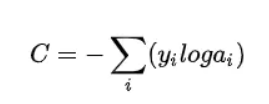 4076491-df2df44a4131abc2
4076491-df2df44a4131abc2
二分类对应的神经网络的最后一层为sigmoid。
例子:
1
2
3
4
5
6
| >>> y_true = [[0, 1], [0, 0]]
>>> y_pred = [[0.6, 0.4], [0.4, 0.6]]
>>> loss = tf.keras.losses.binary_crossentropy(y_true, y_pred)
>>> assert loss.shape == (2,)
>>> loss.numpy()
array([0.916 , 0.714], dtype=float32)
|
最终返回二分类任务交叉熵损失值,形如[batch_size, d0, .. dN-1]
categorical_crossentropy 函数
1
2
3
4
5
6
| tf.keras.losses.categorical_crossentropy(
y_true,
y_pred,
from_logits=False,
label_smoothing=0
)
|
作用:
计算多分类任务交叉熵损失。
多分类任务交叉熵损失函数如下所示:
 4076491-092ff05a2d62df08
4076491-092ff05a2d62df08
多分类对应的神经网络的最后一层为softmax。
例子:
1
2
3
4
5
6
| >>> y_true = [[0, 1, 0], [0, 0, 1]]
>>> y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
>>> loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred)
>>> assert loss.shape == (2,)
>>> loss.numpy()
array([0.0513, 2.303], dtype=float32)
|
最终返回多分类任务交叉熵损失值。
sparse_categorical_crossentropy 函数
1
2
3
4
5
6
| tf.keras.losses.sparse_categorical_crossentropy(
y_true,
y_pred,
from_logits=False,
axis=-1
)
|
作用:
计算稀疏多分类任务交叉熵损失。
例子:
1
2
3
4
5
6
| >>> y_true = [1, 2]
>>> y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
>>> loss = tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred)
>>> assert loss.shape == (2,)
>>> loss.numpy()
array([0.0513, 2.303], dtype=float32)
|
最终返回稀疏多分类任务交叉熵损失值。
poisson函数
1
2
3
4
| tf.keras.losses.poisson(
y_true,
y_pred,
)
|
作用:
计算标签值和预测值之间的泊松loss。
泊松损失是张量y_pred - y_true * log(y_pred)元素的平均值。
例子:
1
2
3
4
5
6
7
8
| >>> y_true = np.random.randint(0, 2, size=(2, 3))
>>> y_pred = np.random.random(size=(2, 3))
>>> loss = tf.keras.losses.poisson(y_true, y_pred)
>>> assert loss.shape == (2,)
>>> y_pred = y_pred + 1e-7
>>> assert np.allclose(
... loss.numpy(), np.mean(y_pred - y_true * np.log(y_pred), axis=-1),
... atol=1e-5)
|
最终返回泊松损失值,形如[batch_size, d0, .. dN-1]。
当y_true和y_pred有不兼容的形状时报错:InvalidArgumentError
kl_divergence函数
1
2
3
4
| tf.keras.losses.kl_divergence(
y_true,
y_pred,
)
|
作用:
计算标签值和预测值之间的Kullback-Leibler散度loss。
loss的计算公式为:loss = y_true * log(y_true / y_pred)。
例子:
1
2
3
4
5
6
7
8
| >>> y_true = np.random.randint(0, 2, size=(2, 3)).astype(np.float64)
>>> y_pred = np.random.random(size=(2, 3))
>>> loss = tf.keras.losses.kullback_leibler_divergence(y_true, y_pred)
>>> assert loss.shape == (2,)
>>> y_true = tf.keras.backend.clip(y_true, 1e-7, 1)
>>> y_pred = tf.keras.backend.clip(y_pred, 1e-7, 1)
>>> assert np.array_equal(
... loss.numpy(), np.sum(y_true * np.log(y_true / y_pred), axis=-1))
|
最终返回Kullback-Leibler散度损失值。
如果y_true不能被转换为y_pred的类型时报错:TypeError
损失函数对于神经网络的训练极其重要,一个适当的损失函数可以大大加快神经网络的训练速度,以及帮助神经网络找到最优解。所以如果想要科学构建神经网络,一定要将损失函数了解透彻,希望大家下去多多查阅相关资料,巩固知识。谢谢大家耐心观看!