畅游人工智能之海--Keras教程之高级激活层
畅游人工智能之海--Keras教程之高级激活层
各位读者大家好,今天我们要一起来学习Keras的高级激活层,它实际上就是激活函数的Model类API用法,与激活函数效果相同。激活层是非常重要的网络层,它将非线性变化引入了网络中,使网络可以任意逼进任何非线性函数中,给了神经网络更加强大的功能。没有激活函数的每层都相当于矩阵相乘,就算你叠加了若干层之后,无非还是个矩阵相乘罢了。可以说神经网络的成功与激活层密不可分。那接下来就让我们开始今天的学习吧!
LeakyReLU层
1 | keras.layers.LeakyReLU(alpha=0.3 #alpha: float >= 0。负斜率系数 |
作用:
LeakyRelU是修正线性单元( Rectified Linear Unit, ReLU)的特殊版本,当不激活时, LeakyReLU仍然会有非零输出值,从而获得一个小梯度,避免ReLU可能出现的神经元“死亡”现象。
当神经元未激活时,它仍允许赋予一个很小的梯度: f(x)=max(0,x)+negative_slope×min(0,x), 其中,negative_slope是一个小的非零数。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输入尺寸:
可以是任意的。如果将该层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同
PReLU层
1 | keras.layers.PReLU(alpha_initializer='zeros', #权重的初始化函数 |
功能:
该层为参数化的ReLU( Parametric ReLU)。
形如 f(x) = alpha * x for x < 0, f(x) = x for x >= 0, 其中 alpha 是一个可学习的数组,尺寸与 x 相同。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
ELU层
1 | keras.layers.ELU(alpha=1.0 #负因子的尺度 |
功能:
ELU层是指数线性单元( Exponential Linera Unit)。
形如 f(x) = alpha * (exp(x) - 1.) for x < 0, f(x) = x for x >= 0
输入大小:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出大小:
与输入相同。
ThresholdedReLU层
1 | keras.layers.ThresholdedReLU(theta=1.0 #theta: float >= 0。激活的阈值位 |
功能:
该层是带有门限的ReLU
形式: f(x) = x for x > theta, 否则f(x) = 0。
输入:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出:
与输入相同。
Softmax层
1 | keras.layers.Softmax(axis=-1 #整数,应用 softmax 标准化的轴 |
功能:
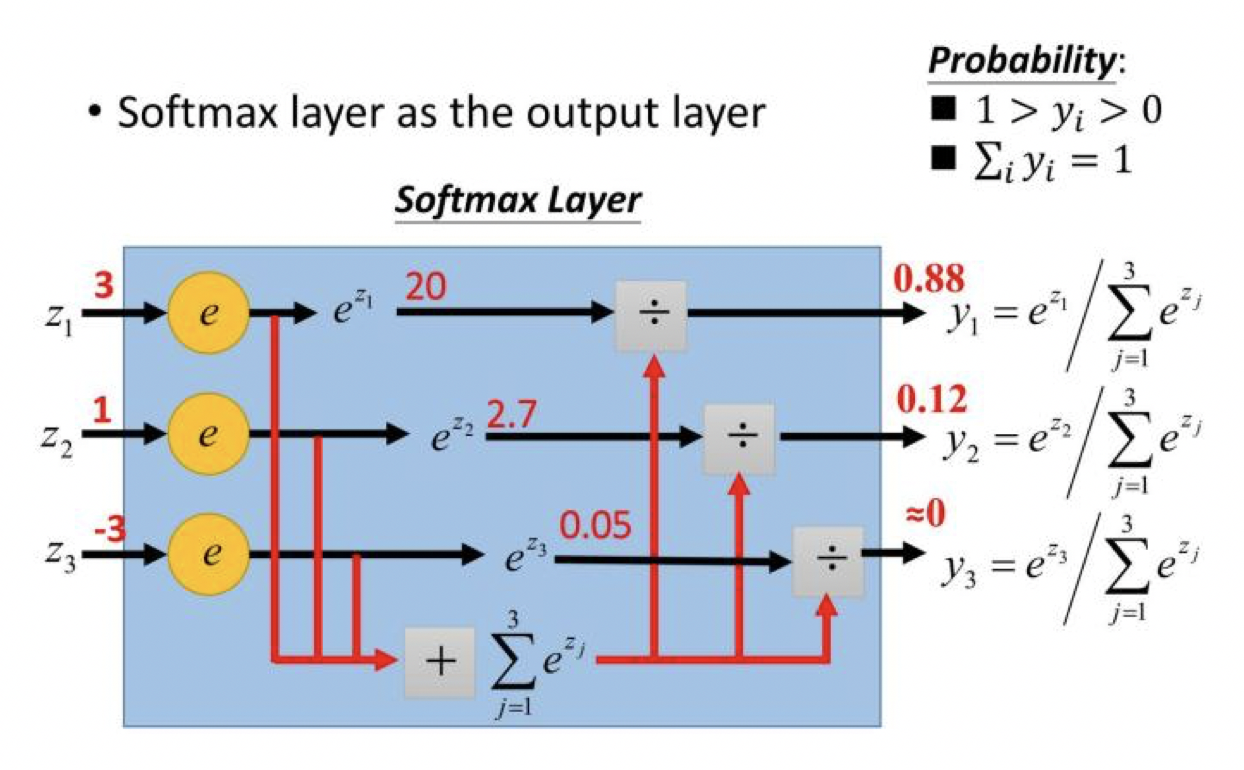
softmax把一个k维的real value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….)其中bi是一个0-1的常数,然后可以根据bi的大小来进行多分类的任务。公式如下:
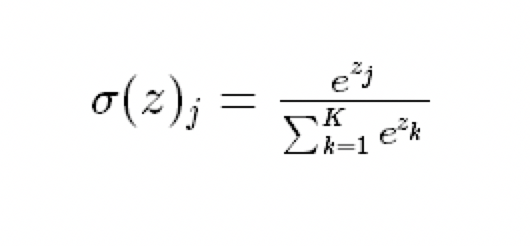
应用实例:
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
ReLU层
1 | keras.layers.ReLU(max_value=None, #浮点数,最大的输出值 |
功能:
Relu是最常用的默认激活函数,若不确定用哪个激活函数,就使用Relu或者LeakyRelu
Relu激活函数(The Rectified Linear Unit),用于隐层神经元输出。公式如下
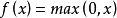
函数图像如下:
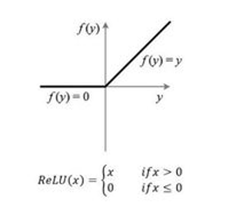
它与其他激活函数最大的不同在于它是线性的,因而不存在梯度爆炸的问题,在多层网络结构下梯度会线性传递。
在深度学习中Relu是用的最广泛的一种激活函数。
使用默认值时,它返回逐个元素的 max(x,0)。
否则:
- 如果
x >= max_value,返回f(x) = max_value, - 如果
threshold <= x < max_value,返回f(x) = x, - 否则,返回
f(x) = negative_slope * (x - threshold)。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
相信大家经过今天的学习,能够对高级激活层的类型和功能有一个清晰的认知,激活层是非常重要的网络层,对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用,它们给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。 所以希望各位能亲手实践以对它有更好地认识,大家一起加油!