优化器
写在开篇
各位读者朋友大家好,昨天我们已经学习了一部分Keras的优化器,今天我们将完成优化器剩余部分的学习。
自适应学习率优化算法针对于机器学习模型的学习率,然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
类型说明
Adamax类
1 | tf.keras.optimizers.Adamax( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, name="Adamax", **kwargs) |
它是Adam算法基于无穷范数(infinity norm)的变种。默认参数遵循论文中提供的值。
参数w随着梯度g更新的更新规则如下:
1 | t += 1 |
伪代码:

参数
- learning_rate: 学习率。
- beta_1: 第1阶矩估计的指数衰减率。
- beta_2: 指数加权无穷范数的指数衰减率。
- epsilon: float >= 0. 模糊因子. 若为
None, 默认为K.epsilon()。与“Adam”类似,加入的epsilon是为了数值稳定性。 - name: 应用梯度时创建的操作的可选名称。默认为“Adamax”。
- **kwargs: 关键字参数。允许是'"clipnorm" 或 "clipvalue" 。"clipnorm" 按照norm裁剪梯度值;"clipvalue"按照value裁剪梯度的值。
Nadam类
1 | tf.keras.optimizers.Nadam( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, name="Nadam", **kwargs) |
Adam本质上像是带有动量项的RMSprop,Nadam就是带有Nesterov 动量的Adam RMSprop.
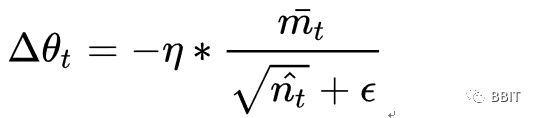
其中默认参数来自于论文,推荐不要对默认参数进行更改。
可以看出,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
Ftrl类
1 | tf.keras.optimizers.Ftrl( learning_rate=0.001, learning_rate_power=-0.5, initial_accumulator_value=0.1, l1_regularization_strength=0.0, l2_regularization_strength=0.0, name="Ftrl", l2_shrinkage_regularization_strength=0.0, **kwargs) |
FTRL(Follow-the-regularized-Leader)优化器
实验证明,L1-FOBOS这一类基于梯度下降的方法有较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。FTRL综合考虑了FOBOS和RDA对于正则项和W的限制,从而结合了二者的优点。
Arguments
- learning_rate_power: 控制在训练期间学习率的降低。如果想用固定的学习速率,请置为0。
- initial_accumulator_value: accumulators的初始值。
- l2_shrinkage_regularization_strength: 这个L2收缩是一个量值惩罚。当输入是稀疏的时候,收缩只会发生在活跃的权重上。
Ftrl在处理诸如逻辑回归之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色。
写在文末
优化器对于神经网络来说非常重要,不同的优化方式有不同的效果,应该针对样本进行选择,以实现更好的优化效果,希望大家在学习之余也多多查阅相关资料,更加牢固地掌握这一知识。谢谢大家的阅读。