嵌入层
畅游人工智能之海 带你学习Keras的嵌入层
写在开篇
mbedding 实际上是一种映射,将单词从原先的表示映射到新的多维空间中,在这个多维空间中,词向量之间的距离表征了单词之间的语义相关性。例如,cat 和 kitten语义相近,而cow和cat语义相差就比较远,因此一个好的嵌入模型应该能正确的将cat 和kitten放的比较近,同时cat和cow的距离相对较远。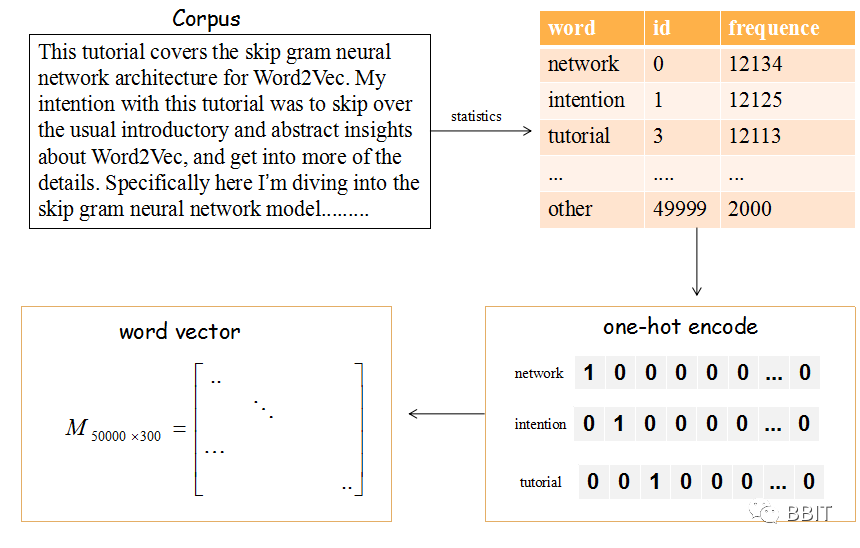
类型说明
Embedding
嵌入层 其作用是将正整数(索引值)转换为固定尺寸的稠密向量。例如:[[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]],只能用作模型中的第一层。
1 | keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None) |
例子
1 | model = Sequential() |
参数
- input_dim: int > 0。词汇表大小, 即,最大整数 index + 1。
- output_dim: int >= 0。词向量的维度。
- embeddings_initializer:
embeddings矩阵的初始化方法 - embeddings_regularizer:
embeddingsmatrix 的正则化方法 - embeddings_constraint:
embeddingsmatrix 的约束函数 - mask_zero: 是否把 0 看作为一个应该被遮蔽的特殊的 "padding" 值。这对于可变长的 循环神经网络层 十分有用。如果设定为
True,那么接下来的所有层都必须支持 masking,否则就会抛出异常。如果 mask_zero 为True,作为结果,索引 0 就不能被用于词汇表中 (input_dim 应该与 vocabulary + 1 大小相同)。
input_length: 输入序列的长度,当它是固定的时。如果你需要连接 Flatten 和 Dense 层,则这个参数是必须的 (没有它,dense 层的输出尺寸就无法计算)。
输入尺寸
尺寸为 (batch_size, sequence_length) 的 2D 张量。
输出尺寸
尺寸为 (batch_size, sequence_length, output_dim) 的 3D 张量。
keras中的Embedding层有两种词嵌入的方式,如果需要语义特征,可以使用预训练的方式,通过参数指定预训练词向量矩阵,该词向量矩阵可以是基于任何语言模型,如Word2vec、Glove等。如果不需要语义特征,还有另一种方式是随机初始化,Embedding在随机初始化方式下是一个全连接层,而后面得到的词表示是全连接层的权重参数。
实验例子
利用GloVe预训练词向量对新闻文本进行分类
篇幅有限,只保留主要部分,所有代码请参考 在Keras模型中使用预训练的词向量
数据预处理:
先遍历下语料文件下的所有文件夹,获得不同类别的新闻以及对应的类别标签
Embedding layer设置:
接下来,从GloVe文件中解析出每个词和它所对应的词向量,并用字典的方式存储
1 | embeddings_index = {} |
此时,我们可以根据得到的字典生成上文所定义的词向量矩阵
1 | embedding_matrix = np.zeros((len(word_index) + 1, EMBEDDING_DIM)) |
现在将这个词向量矩阵加载到Embedding层中,注意,trainable=False使得这个编码层不可再训练。
1 | from keras.layers import Embedding |
一个Embedding层的输入应该是一系列的整数序列,比如一个2D的输入,它的shape值为(samples, indices),也就是一个samples行,indeces列的矩阵。每一次的batch训练的输入应该被padded成相同大小。所有的序列中的整数都将被对应的词向量矩阵中对应的列(也就是它的词向量)代替,比如序列[1,2]将被序列[词向量[1],词向量[2]]代替。这样,输入一个2D张量后,我们可以得到一个3D张量。
训练1D卷积
最后,可以使用一个小型的1D卷积解决这个新闻分类问题。
1 | sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32') |
在两次迭代之后,这个模型最后可以达到0.95的分类准确率(4:1分割训练和测试集合)。也可以利用正则方法(例如dropout)或在Embedding层上进行fine-tuning获得更高的准确率。
作为对比,也可以直接使用keras自带的Embedding层训练词向量而不用GloVe向量。
1 | embedding_layer = Embedding(len(word_index) + 1, |
写在文末
相信大家经过今天的学习,能够获得对embedding层有一个初步的认识,感兴趣的小伙伴可以自己动手做做实验,我们下次见!