主动情感领域适应
主动情感领域适应
1. 摘要
情感分析领域现有的方法通常依赖于在源域训练的情感分类器。如果情感特征在源域和目标域的分布存在显著差异,性能会显著下降。在本文中,作者提出了一种主动情绪域适应方法来处理这个问题。该方法利用少量的标记样本在主动学习模式下进行选择和标注,使通用情感词典适应目标领域。
2. 介绍
在情感分类任务中,不同的领域通常有许多不同的情感表达。此外,相同的单词或短语在不同领域可能代表不同情绪。因此,为每个领域分别标注情感词典是不切实际的。
该论文,综合了普遍的情感信息和少量主动选择的目标域标记样本。通过使用特定领域词汇之间的情感相似性,将从情感词汇中提取的一般情感信息转换为适应目标领域的信息。然后从目标领域中选择并注释少量的样本用以训练模型。这些标记样本可以提高目标域情绪适应的性能。
3.方法
3.1 符号介绍
通用情感信息:p ∈RD×1 ,D为单词表大小,如果pi = 1(积极) / -1(消极),w∈RD×1表示使用的模型(这里使用的是线性模型),f(xi,yi,w)表示使用w模型对第i条文本进行分类得到的损失值,xi是第i条文本的特征向量,yi∈ {1,-1}。损失函数如下: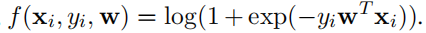
3.2 特定域情感相似性
- 基于语法规则:如果两个词含有相同的词性标签(形容词,动词,副词...)并通过连接词‘and’连接,则假设他们有相同的极性;但如果被‘but’连接,则假设他们有相反的极性。
Sr:未标记文本的词i与j的情感相似度:
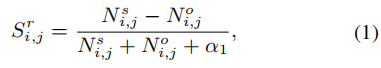
Ns i,j 和No i,j 分别表示根据语法规则,i和j两个词在原语料中的情感相同的频率和情感相反的频率,α1是平滑系数。
- 基于词语间的共现模式:频繁地同时出现的单词不仅有很高的概率具有相似的语义,而且往往具有相似的情感。
Sc:未标记文本的词i与j的情感相似度:
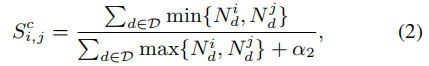
D: 文本集,Nid为文档d中出现的单词i的频率,α2是平滑系数。
- 虽然Sr可靠性更高,但是他的要求相对严格,搜索到的词较少,而Sc计算出来的结果覆盖面更广,但可靠性较低。这里通过是同一种调和平均的方式计算最终的相似度值:Si,j = θSri,j + (1-θ)Sci,j 。改论文中使用的θ值为0.5。
3.3 初始情感分类器
构造初始情绪分类器来启动主动学习过程。现有方法为:随机选择一组未标记的样本进行标注,然后对初始分类器进行训练。然而,随机选取的数据常会导致很差的结果。在本文中,提出通过计算目标领域词之间的情感相似性,将一般的情感信息调整到目标领域,构建初始的情感分类器: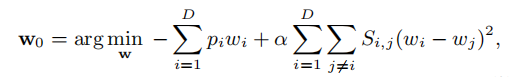
w0 ∈ RD×1 是初始情感分类器,α是一个正则化系数,*p**i*是情感词表中第i个词的先验情感极性,Si,j为i字词与j字词之间的情感相似度得分。
3.4 查询策略
一个重要的问题是如何测量未标记样本的信息量。在本文中,作者选择分类不确定性作为信息度量,这在许多主动学习方法中已被证明是有效的。未标记实例x的分类不确定性定义为:
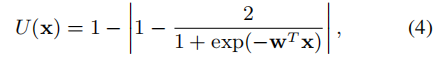
其中w为线性情绪分类模型。U(x)的取值范围是[0,1]。|wTx|越大,当前情绪分类器对该实例的分类有信心,则U(x)会很低。如果|wTx|接近于0,那么这个实例的不确定性会越高。这类实例进行注释并将其添加到训练集是有益的,因为它可以提供未知的情绪表达式的信息。
然而,许多研究人员发现,具有高不确定性的未标记实例可能是异常值,因此,这里作者结合了不确定性和代表性来避免异常值。一种基于k近邻的密度作为代表性测度被表示为:
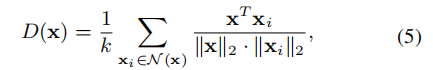
其中N(x)是x最相似的k个实例的集合。未标记样本的最终信息量分数是不确定性和密度的线性组合,公式如下:
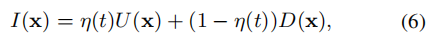
η(t)∈[0, 1]是第t次迭代的迭代系数。在本文中,作者选择一个单调递增函数η(t)。η(t) = 1 /(1 + exp (2−4*t/T)),其中t是迭代的次数。
3.5 主动情绪域适应
与传统的基于原领域训练得到的情感分类器进行转化的方法不同, 该论文的方法如下:
首先,建立一个初始的情感分类器,利用从目标域的未标记样本中挖掘出的词之间的情感相似性,将普遍情感信息调整到目标域。
其次,根据式(5)计算U中每个未标记样本的密度值,并重复以下步骤,直到标注预算用完:
- 首先,根据式(4)计算每个未标记样本的不确定度
- 然后根据式(6)将不确定度和密度结合起来计算它们的信息量。
- 接下来,作者从U中选择信息量最大的未标记样本,并手工标注其标记极性。
- 再将其添加到标记的样本L集合中,并将其从u中移除。
之后,作者基于一般的情感信息p、标记的样本和域特定情感相似性S对目标域的情感分类器进行再训练:
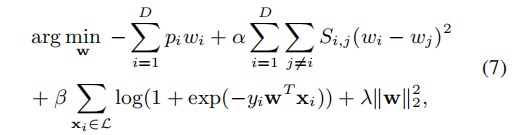
当前轮次由(7)训练的情感分类器在主动情感域适应的下一次迭代中被进一步使用,直到所有人工标注的预算都被使用完。
最后得到目标域的情感分类器。
4.实验结果

表1:亚马逊产品评价数据集
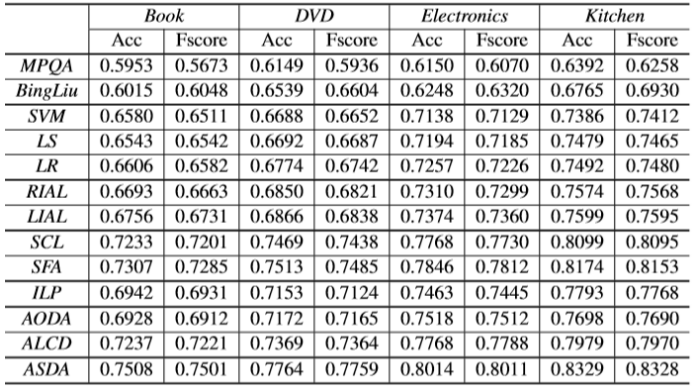
表2:不同方法在不同领域的情绪分类性能。Acc和Fscore分别代表准确率和宏观平均Fscore。
5.结论
在基准数据集上的实验结果表明,该方法能够训练出准确的情绪分类器,同时减少了人工标注的工作量。