基于属性图卷积网络的属性级情感分类
基于属性图卷积网络的属性级情感分类
1. 摘要:
注意力机制和卷积神经网络在属性级(aspect-based)情感分类中得到了广泛的应用。但是,这些模型未考虑句法约束,因此可能会将语法上不相关的上下文词作为判断情感的线索。本文提出基于句法关系树上,构建一个图卷积网络(GCN)来利用句法信息和词的依赖关系。在三个基准测试集合上的实验表明,本文提出的模型与一系列最优模型具有相当的效果,并进一步证明了图像卷积结构能够正确地捕获语法信息和远位词依赖。
2. 介绍
由于手工特征细化的低效,早期属性级情感分类主要基于神经网络方法。自发现语法关系对于属性词查找的重要作用以来,注意力机制与递归神经网络(RNNs)相结合的方法成为了首选。虽然基于注意力的模型很有前途,但它们不足以捕捉上下文词和句子中的属性词之间的句法依赖。另外,基于CNN的模型只能考察连续的多词与卷积操作词序列,但无法确定由多个不相邻的词描述的情感。
论文的目标是使用图卷积网络(GCNs)解决上述两个问题。GCN有一个多层架构,每一层根据邻居节点的属性实现编码操作和更新操作。通过语法依存关系,GCN能够推算与目标属性在语法上相关的单词,并长期的使用多单词关系和语法信息。为了将GCNs有效地用于属性级情感分类,文提出了一种特定方面的图卷积网络(ASGCN)。它是第一个基于GCN的属性级情感分类模型。
3. 图卷积神经网络
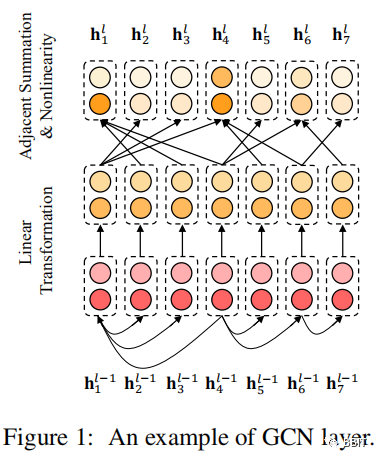
GCNs可以看作是对传统的CNNs的一种改造,用于编码非结构化数据的局部信息。对于给定的k个节点的图,通过对图进行枚举,得到邻接矩阵A∈Rk×k。为了方便起见,定义第l层第i个结点的输出为\(h_i^l\),其中\(h_i^0\)表示第i个结点的初始状态。对于一个L层的GCN,l∈[1,2,...,L], \(h_i^L\)是结点i的最终状态。在结点表示上的图卷积操作可以写成: \[ h_i^l = \sigma(\sum_{i=1}^{k}A_{ij}W^lh_j^{l-1}+b^l) \] 其中Wl为线性变换权值,bl为偏置项,而σ为激活函数。为了更好地说明,见图1。
4. 特定于方面的图卷积网络
4.1 嵌入和双向LSTM
给定一个包含n个单词的句子c={\(w^c_1\),\(w^c_2\),\(w^c_3\),...,\(w^c_{r+1}\),...,\(w^c_{r+m}\),...,\(w^c_{n-1}\),\(w^c_n\)},该句子包含一个从第r+1个token开始的m-word 的属性词。使用嵌入矩阵E∈R|V|×de将每个单词标记嵌入到一个低维实值向量空间中,其中|V|是词汇量的大小,de表示单词嵌入的维数。利用句子的单词嵌入构造一个双向LSTM来生成隐藏状态向量Hc = {\(h^c_1\),\(h^c_2\).,...,\(h^c_n\)},\(h^c_t\)为双向LSTM在时间t时的隐藏状态向量。
4.2 获得属性词特征
在本研究中,通过在句子的句法依赖树上应用多层图卷积,并在其顶部施加一个面向属性的屏蔽层(masking layer)来获得属性层次的特征。
4.2.1 依赖树的图卷积
在构造了给定句子的依赖树之后,首先根据句子中的单词得到邻接矩阵A∈\(R^{n x n}\)。本文提出了两种ASGCN变体,即无方向性依赖图上的ASGCN- DG和有方向性依赖树上的ASGCN- DT。实际上,ASGCN-DG和ASGCN-DT唯一的区别在于它们的邻接矩阵。注意,每个单词都被手工设置为与自身相邻,即对角线值均为1。
ASGCN变体以多层方式执行,在4.1节的双向LSTM输出之上,即H0= Hc以使节点感知上下文。然后用归一化因子对每个节点的表示进行图卷积运算更新如下: \[ \tilde{h}_i^{l}=\sum_{j=1}^nA_{ij}W^lg_j^{l-1} \] 在 $g^{l-1}_j $∈ R2dh是 第j个token的表示。而 \(h^l_i\)∈ R2dh 是当前层的产物, 是这棵树中第i个token的度。权重Wl和偏差bl是训练参数。
值得注意力的是,本文并没有立即将\(h^l_i\)送入连续的GCN层,而是首先进行位置感知转换: \[ g_i^l=\textit{F}(h_i^l) \] 其中F(·)是一个分配位置权重的函数,用来增加靠近属性词的上下文词的重要度。具体来说,函数F(·)为: \[ q_i=\left\{\begin{matrix} 1-\frac{\tau+1-i}{n} & 1\leqslant i< \tau+1 \\ 0 & \tau+1\leqslant i \leqslant\tau+m \\ 1-\frac{+i-\tau-m}{n} & \tau+m < i \leqslant n \end{matrix}\right. \\ \]
\[ F(h_i^l)=q_ih_i^l \]
其中qi∈R为第i个token的位置权值。L层GCN的最终结果为HL = {h\(^L_1\), h\(^L_2\),···,h\(^L_{r +1}\),···,\(h^L_{r+m}\),···,h\(^L_{n-1}\), h\(^L_n\)}, h\(^L_t\)∈R2dh。
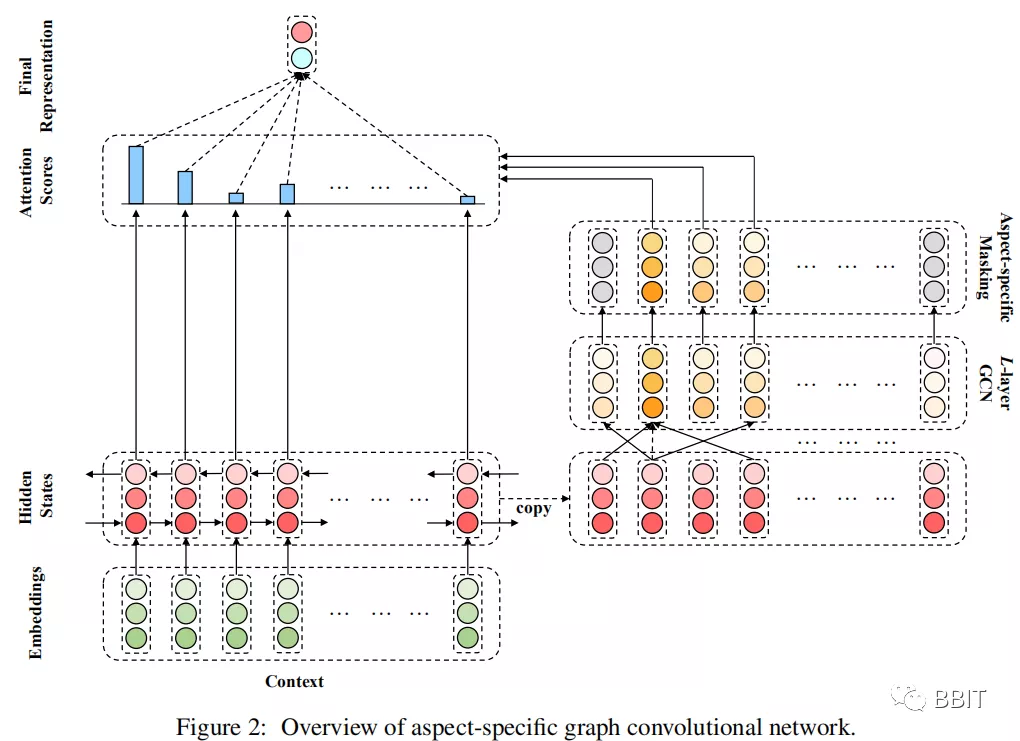
4.2.2Aspect-specific Masking
在这一层中,屏蔽了非属性词的隐藏状态向量,并保持属性词状态不变: \[ h_t^L = 0 \qquad \qquad 1\leqslant t < \tau+1,\qquad \tau+m\leqslant t < n \] zero-masking层的输出是面向属性的表示$H^L_{mask} \(={0,···,\)hL_{r+1}\(,···,\)hL_{r+m}$,···,0}。
4.3 Aspect-aware Attention
基于面向属性的表示,通过一种新的基于检索的注意力机制生成了隐藏状态向量Hc的细粒度表示。其思想是从隐藏状态向量中检索与属性词语义相关的重要特征,并相应地为每个上下文词设置基于检索的注意力权重。在实现中,注意力权值的计算如下: \[ \beta = \sum_{i=1}^nh_t^{cT}h_i^L = \sum_{i=\tau+1}^{\tau+1}h_t^{cT}h_i^L \]
\[ \alpha_t=\frac{exp(\beta_t)}{\sum_{i=1}^nexp(\beta_i)} \]
预测的最终表示形式为:
4.4 情感的分类
得到表示r后,将其送入全连接层,然后使用softmax归一化,得到概率分布p∈Rdp: \[ p = softmax(W_pr+b_p) \] 4.5 训练
该模型采用标准梯度下降算法进行训练,并使用交叉熵损失和L2正则化:
5. 实验及结论
在三个基准测试集合上的实验表明,本文提出的模型与一系列先进的模型具有相当的有效性,并进一步证明了图像卷积结构能够正确地捕获语法信息和长程单词依赖。
table 1

table 2
本文重新审视了针对特定属性情感分类的现有模型所面临的挑战,并指出了图卷积网络(GCN)对于解决这些挑战的适用性。为此,作者提出了一种采用GCN的属性级情感分类网络。实验结果表明,GCN通过利用句法信息和远程单词依赖关系,提高了整体性能。