机器学习技术在情感分类中的应用
机器学习技术在情感分类中的应用
1. 简介
为了帮助用户更好的组织、查找、筛选信息,对文本进行分类管理是必然的。在文本分类方面,按情感倾向进行分类的方法也是当下的主流研究问题之一。一方面是这类数据越来越多;另外,情感分类也可以应用于商业智能应用和推荐系统。当使用影评作为数据进行文本分类时,传统机器学习的效果要高于基于人工方法的正确率,但是,和利用主体进行分类的发放比有所不足。主题通常是通过一些关键词来得到,而文本情感的表达确实多样的,这无疑增大了情感分类任务的难度,因为想要准确获取情感,我们可能需要让机器去“理解”文本。所以该论文研究了机器学习技术在情感分类问题中的应用效果的同时,还分析了这个问题,以便更好地了解它有多困难。
2. 方法
2.1 数据选取与预处理
该论文选区的Internet Movie Database(IMDb),并且只使用了并设计了星级或数字到积极、消极、中性三情感的映射。为了防止结论受
2.2 对照组设计
由于人类对于文本情感分类的准确程度很高,而这很大程度上会依赖文本中的一些字符或词,所以,请了两位学生分别完成提取评论中具有情感色彩的菜或字符,后使用这些单词作为特征,进行文本分类。
如图一所示是两位学生分别提取的关键词以及最终的分类准确率:58%, 64%。Ties表示两种情绪具有相同可能性的文档数百分比。而这高Ties指标说明了有大量无法通过词汇列表判断情感倾向的文本,人工生成的列表的简洁性是导致性能结果相对较差的一个因素。但并不是只有列表的大小就能限制准确性,如图二所示,这是一个具有7个积极词和7个消极词的列表,他的准确率达到了69%且具有较低Ties指标。而其中包含了诸如‘?’或是‘!’之类的字符。这说明了某些符号可能也代表着作者的强烈情感倾向。
2.3 机器学习方法介绍
接下来的研究目的是检验是否将情绪分类简单地视为基于主题的分类的一个特例(两个“主题”是积极情绪和消极情绪),或者是否需要开发特殊的情绪分类方法。
文本的编码方法是:假设:F = {f1,f2,..., fm}是一些特征词,而
Ni(d)表示了第d个文本中特征词fi出现的次数。这样就可以将一个文本编码成了一个向量D = (N1(d),...,Nm(d))。
主要使用如下三种机器学习方法。
- 朴素贝叶斯
该方法通过分配给当前文档一个具有最大概率的类别 \[ c^*=\arg\max_cP(c|d) \] 而P(c|d) 的获得是通过贝叶斯定律: \[ P(c|d)=\frac{P(c)*P(d|c)}{P(d)} \] 又因为P(d)表示了选取文档d的概率,是一个和c无关的概率,所以可以简化成: \[ P(c|d)=P(c)*P(d|c) \] P(c)表示了类别c的先验概率,通过统计训练集中c类别文档数占文档总数即可。下面主要介绍P(d|c)的获得:
朴素贝叶斯假设:每个特征词之间是条件独立的,这种独立性使得我们不需要再计算它们的概率时将其他的特征加到条件里,也就是说我们可以直接假期展开为: \[ P(d|c)=\prod_{i = 1}^mP(f_i|c)^{N_i(d)} \] P(fi|c)则表示了类别c中出现关键词fi的概率,也是可以通过统计得到的。这里要说的一点是:朴素贝叶斯的假设在现实世界中是不合理的,但是他的分类效果确实比较不错的。
- 最大熵
该方法在某些情况下分类效果要优于朴素贝叶斯。它对P(c|d)的计算公式是: \[ P_{ME}(c|d)=\frac{1}{Z(d)}exp(\sum_i\lambda_{i,c}F_{i,c}(d,c)) \] Z(d)是一个正则化函数。F是一个映射:(特征词,类别) -> {0, 1}。定义为: \[ F_{i,c}=\left\{\begin{matrix} 1 & N_i(d)>0\quad and\quad c'=c \\ 0 & others \end{matrix}\right. \] λi,c是特征权重,其值越大,表明特征fi对类别c的贡献程度越大。参数值的最终训练结果可最大化归纳分布的熵。
- 支持向量机
该方法通常要优于朴素贝叶斯方法。在二分类的情况,该方法可以理解成寻找一个高纬度平面--超平面,将正例数据与反例数据分隔开并使得数据到超平面的边距也尽可能大。对于这样超平面的搜索可以当作一个约束优化问题进行求解,这里给出超平面w的求解公式: \[ \vec{w}=\sum_j\alpha_jc_j\vec{d}_j \qquad \alpha_j > 0 \] 表示第j个文本向量,, 其中1表示积极情感,-1表示消极情感。αj是通过求解对偶优化问题获得。
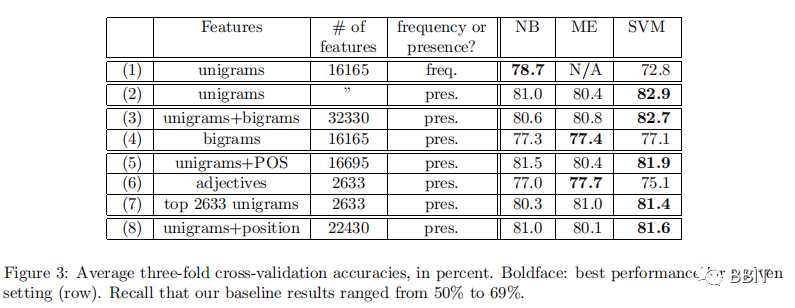
3. 结论
如图3,与对照组相比,通过机器学习技术生成的结果非常好。在相对性能方面,Naive Bayes往往做得最差,而SVMs往往做得最好,尽管差异不是很大。