神经网络加速
神经网络加速
各位读者大家好,我们今天来介绍一些神经网络加速相关的内容。
深度神经网络的复杂性和可移植性直接影响了人工智能技术在现实生活中的应用,因此人们开始研究神经网络的加速和压缩。
神经网络加速技术介绍
近年来提出的网络结构趋势是层数越来越深,参数量和计算量越来越大。从LeNet-5(共约30万参数)到GPT-3(1750亿参数),对运算量的需求限制了这些模型的应用场景。例如移动设备、嵌入式设备这样存在计算、体积、功耗等方面受限的设备,它们也需要应用深度学习技术。由于这些设备存在的约束,导致现有的高性能深度神经网络无法在上面进行有效的计算和应用。
那么,如何在保持现有神经网络性能基本不变的情况下,通过将网络的计算量大幅减小,以及对网络模型存储做大幅的削减,使得网络模型能在资源受限的设备上高效运行的问题,成为了研究深度神经网络加速、压缩的基本动机。
图1.由多个全连接层堆叠而成的深层神经网络
目前网络加速和压缩技术大概可以分为低秩分解、模型裁剪、量化、Knowledge Distillation等等。那么第一种方法低秩分解的原理是用矩阵分析的方法减少神经网络中矩阵运算的计算量。模型裁剪则是通过裁剪神经网络中的链接来减少神经网络模型的大小。量化方法则是针对浮点运算的优化。最后的Knowledge Distillation则是构建新的student网络,将原网络作为teacher网络去训练student网络。
量化技术
量化技术的目的就是使用 8 位或 16 位的整型数来替代浮点数。这并不需要对原模型进行大量的修改,而且适用面广,凡是需要浮点运算的地方都可以量化加速。非常适合一些没有浮点运算的移动设备和嵌入式设备。
神经网络的低比特量化技术是在2016年在google的一篇On the efficient representation and execution of deep acoustic models文章中提出来的。
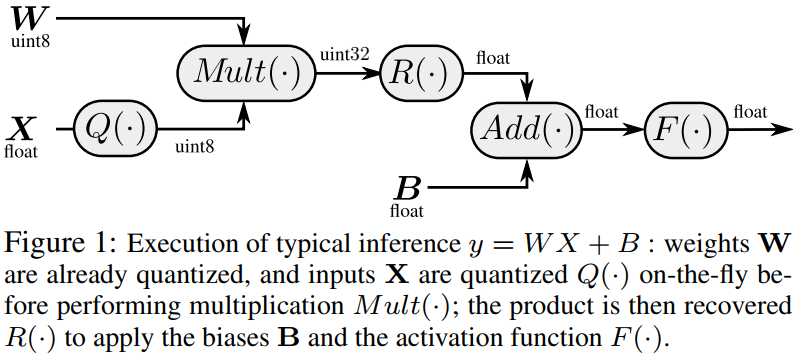
图2.量化计算流程
图2中展示的是计算y = WX + B的量化流程。其中W是神经网络的参数,已经被提前量化处理为8位的无符号整型。X是浮点数输入,计算时用量化函数Q(·)即时量化。量化后的权重W和X相乘,扩展为32位无符号整型。这个结果经过R(·)反量化还原为浮点数,再与偏置矩阵B相加还原出浮点数结果。
从上面的流程描述来看,量化过程的核心是量化函数Q(·)和反量化函数R(·)。
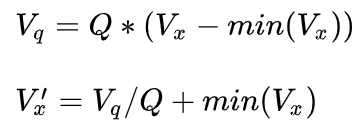
$V_q$表示量化后的整型,而$V_x$是还原出的浮点数。 $Q = S/(max(V_x)-min(V_x))$,$S = 1<<bits-1$。
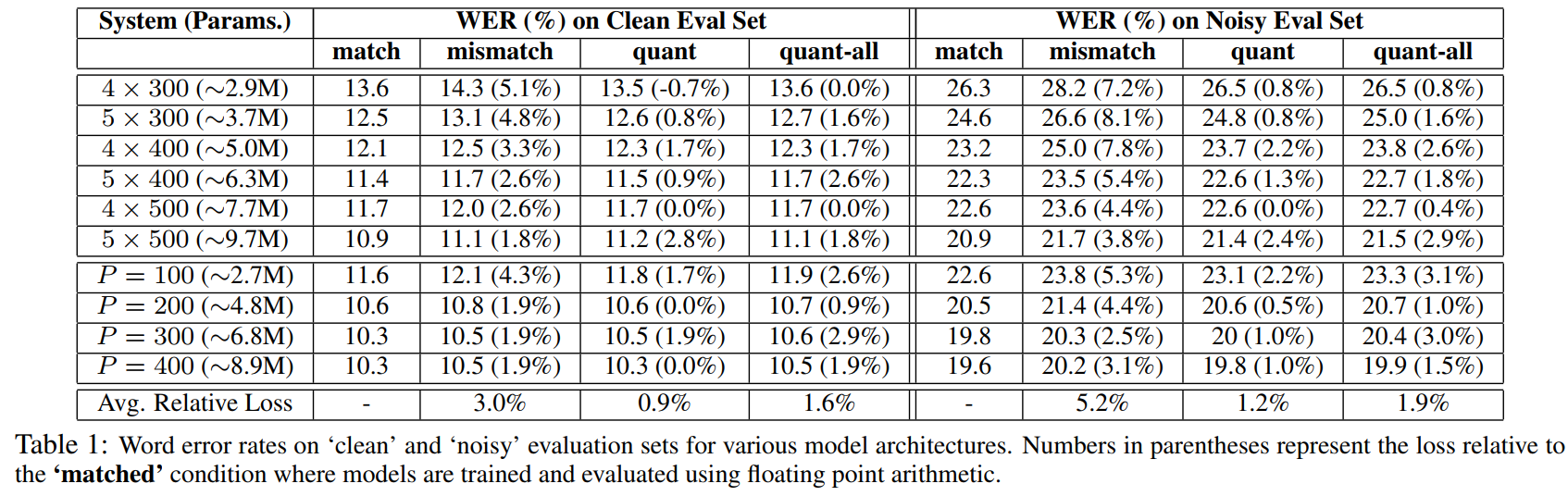
图3.量化误差实验结果。其中match表示训练和测试流程都没有经过量化;mismatch表示训练未量化,测试使用量化技术。quant表示除了网络最后一层的参数之外,训练和测试过程都对网络参数进行了量化;quant-all表示对所有网络层进行了量化。
以上。