Extracting Drug-Drug Interactions with Attention CNNs
0. 摘要
本文提出了一种新的基于注意力机制的卷积神经网络(CNN)的药物-药物相互作用(DDI)提取模型。CNN已经被证明在DDI提取任务上有很大的潜力;然而,尽管注意力机制在一般领域的分类任务中被证明是有效的,但在目标-实体对句子中强调重要词的注意力机制尚未被利用CNN进行研究。我们在DDI提取-2013共享任务的任务9.2上评估了我们的模型。我们的注意力机制提高了基于CNN的基础DDI模型的性能,该模型获得了69.12%的f-score,可以与最先进的模型竞争。 # 1. 介绍
当同时给病人用药时,药物的作用可能会增强或减弱,这可能会引起副作用。这种相互作用被称为药物-药物相互作用(DDIs)。drug bank、Therapeutic Target Database、pharmacgkb等药物数据库,为研究人员和专业人员总结药物和DDI信息;然而,许多新发现的相互作用在数据库中没有涉及,它们仍然埋藏在生物医学文本中。因此,研究从文本中提取DDI信息的DDI自动提取技术,有望支持高覆盖率、快速更新的数据库的维护,帮助医学专家加深对DDI的理解。
对于DDI提取,基于深度神经网络的方法最近引起了相当大的关注。深度神经网络在自然语言处理领域得到了广泛的应用。它们在几个NLP任务中表现出高性能。网络结构通常采用卷积神经网络和循环神经网络。其中,CNN的一个优点是它们可以很容易地并行化,因此用GPU计算速度很快。
Liu等研究表明,基于CNN的模型在DDI提取任务上能够实现较高的精度。Sahu和Anand提出了一种基于注意机制的RNN模型来处理DDI提取任务,并显示了最先进的性能。Wang 等提出将注意机制集成到基于CNN的关系提取中。他们的模型在关系提取任务中表现出了最先进的性能。然而,具有注意机制的cnn在DDI提取任务上并没有得到评价。
本研究提出了一种新的注意机制,并将其整合到基于CNN的DDI抽取模型中。注意机制扩展了Wang 等提出的注意机制,它将匿名实体词与其他词分开处理,并加入了一个平滑参数。
2. 方法
在基于CNN的DDI抽取模型中,我们提出了一种新的注意机制。我们在图1中概述了该模型。给出了从含有药物的句子中提取相互作用的模型。在本节中,我们首先介绍输入句子的预处理。然后介绍了基本的CNN模型,并解释了注意机制。最后,对训练方法进行了说明。 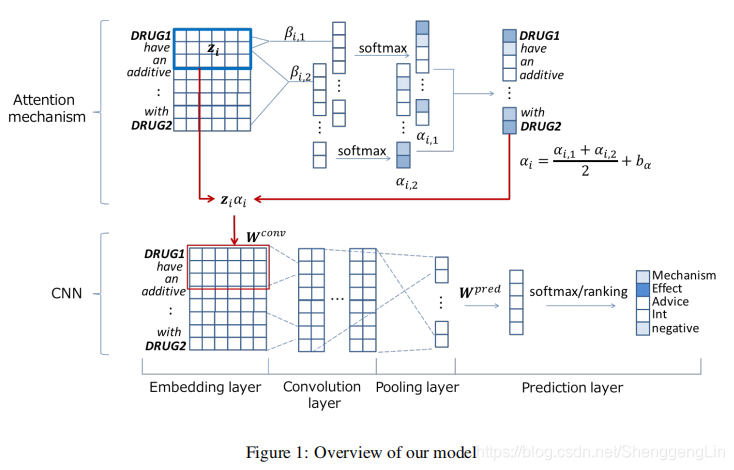 ## 2.1 预处理 在对一个句子中的药物对进行处理之前,我们会根据目标药物的出现顺序,将其替换为“DRUG1”和“DRUG2”。我们也用“DRUGOTHER”来代替其他提到药物的词。
## 2.1 预处理 在对一个句子中的药物对进行处理之前,我们会根据目标药物的出现顺序,将其替换为“DRUG1”和“DRUG2”。我们也用“DRUGOTHER”来代替其他提到药物的词。
表1显示了一个输入句子“Exposure to oral S-ketamine is unaffected by itraconazole but greatly increased by ticlopidine”时的预处理例子,并给出了目标实体对。通过执行预处理,可以提高DDI抽取模型的泛化能力,并能够使用整个上下文的信息来执行DDI抽取。  ## 2.2 基础CNN模型
## 2.2 基础CNN模型
提取DDIs的基本CNN模型是Zeng et al.(2014)提出的。除了他们最初的目标函数,我们采用了dos Santos等人(2015)的基于排名的目标函数。该模型由四层组成:嵌入层、卷积层、池化层和预测层。我们在图1的下半部分显示了CNN模型。(笔者认为,该论文中使用的嵌入层,卷积层,池化层,预测层都是一些常规的方法,因此不再详细介绍)
2.3 注意力机制
我们的注意机制基于Wang等(2016)的输入注意。本文提出的注意机制与基础注意机制的不同之处在于,我们为不同的注意对象准备了不同的注意,并加入了一个偏置来调节注意的平滑性。我们在图1的上半部分说明了注意机制。  ## 2.4 训练方法 使用L2正则化来避免过拟合,优化方法使用Adam。
## 2.4 训练方法 使用L2正则化来避免过拟合,优化方法使用Adam。
3. 实验设定
我们在图2中说明了DDI提取的工作流程。作为预处理,我们使用GENIA tagger对输入的句子进行分词。在本节中,我们将解释数据集、任务、初始嵌入和超参数调优的设置。 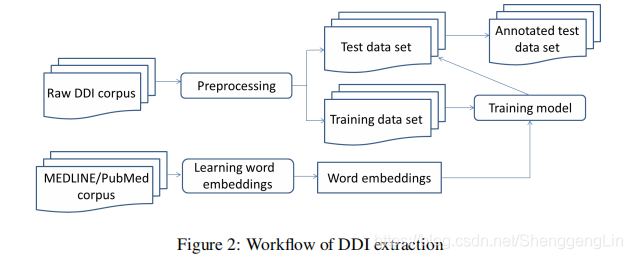 ## 3.1 数据集
## 3.1 数据集
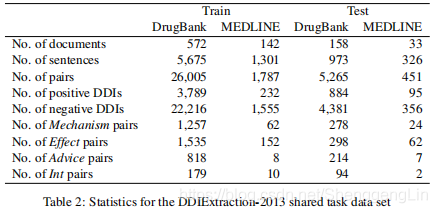
我们使用了来自DDI提取-2013共享任务(SemEval-2013任务9)的数据集进行评估。该数据集由注释了提到药物及其关系的文档组成。该数据集包括两部分:MEDLINE和DrugBank。MEDLINE由PubMed文章的摘要组成,而DrugBank由DrugBank数据库中药物相互作用的描述组成。该数据集注释了以下四种类型的交互。
机制:有一句话描述了DDI的药代动力学机制,例如:Grepafloxacine可能抑制可可碱的代谢。
效果:一个句子代表DDI的效果,例如,“蛋氨酸可以防止庆大霉素的耳毒性作用。”
建议:一句话代表对同时使用两种药物的建议或建议,例如,“alpha -阻滞剂不应与尿毒唑联合使用。”
Int:一个句子仅仅代表一个DDI的发生,没有任何关于DDI的信息,例如:“奥美拉唑和酮康唑的相互作用已经建立。”
数据集统计如表2所示。如表所示,没有相互作用的配对(负配对)的数量大于有相互作用的配对(正配对)。
 ## 3.2 任务设定
## 3.2 任务设定
我们遵循了DDI extract -2013 shared task (SemEval task 9)中task 9.2的任务设置。该任务是将给定的一对药物分为四种交互类型或不交互。我们以每一交互类型的精度(P)、召回(R)和F得分(F),以及所有交互类型的微平均精度、召回和F得分来评估绩效。我们使用任务组织者提供的官方评估脚本,并报告了10次运行的平均值。请注意,我们分别取了精度、召回率和f分数的平均值,所以f分数不能从精度和召回率计算出来。
3.3 初始化嵌入
采用Skip-gram 对词嵌入进行预训练。我们使用2014年MEDLINE/PubMed基线分布,词汇量为1630,978。药物的嵌入,即“drug1”,“drug2”和“druggother”,初始化时都设置为与“drug”相同。训练词在预先训练中没有出现时用均匀分布的随机值进行初始化,并归一化为单位向量。在训练过程中,将训练数据中频率为1的单词替换为“UNK”单词,将训练和预训练中都没有出现的单词嵌入到测试数据集中,并将其嵌入到“UNK”单词中。
3.4 超参整定
表3显示了不需要注意的softmax模型的最佳超参数。我们对其他模型应用了相同的超参数。我们的开发数据集的统计数据如表4所示。我们将卷积窗口的大小设置为[3,4,5],与Kim(2014)相同。词位置嵌入大小从{10,20,30、40、50}中选择,卷积过滤器的大小从{10、50、100、200}中选择,学习速率为{0.01,0.001,0.0001},mini-batch大小为{10、20、50、100、200},L2正则化参数λ为{0.01,0.001,0.0001,0.00001}。 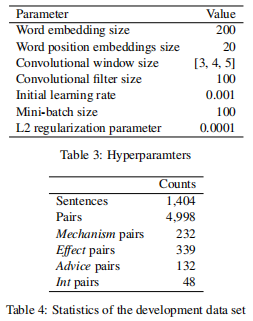
4. 结果
结果证明模型好。
可视化分析: 图3显示了使用我们的注意机制在一些使用DDI对的句子上注意的可视化。在第一句中,“DRUG1”和“DRUG2”有一种机制相互作用。注意机制成功地突出了关键词“concentration”。在第二句具有效果交互作用的句子中,注意机制高度重视“增加”和“效果”。“必要”这个词在第三句建议互动中有很高的权重。对于最后一句的Int交互,“交互”是最突出的。  # 5. 相关工作 在DDI提取-2013共享任务期间和之后,已经提出了各种基于特征的方法。Bj¨orne等人(2013)使用Turku事件抽取系统(TEES)处理DDI抽取,这是一个基于支持向量机(svm)的事件抽取系统。Thomas et al.(2013)和Chowdhury and Lavelli(2013)提出了两阶段处理模型,首先检测出DDIs,然后将提取的DDIs分为四种类型。Thomas et
al.(2013)使用了几种核方法的集合,而Chowdhury和Lavelli(2013)提出了带有负实例滤波的混合核方法。除了我们的模型之外,所有后续模型都使用了反实例过滤。Kim et al.(2015)提出了一种基于两阶段支持向量机的方法,该方法采用了具有丰富特征的线性支持向量机,包括单词特征、词对、依赖关系、解析树结构和基于名词短语的约束特征。我们的模型不使用特征,而是使用CNN。
# 5. 相关工作 在DDI提取-2013共享任务期间和之后,已经提出了各种基于特征的方法。Bj¨orne等人(2013)使用Turku事件抽取系统(TEES)处理DDI抽取,这是一个基于支持向量机(svm)的事件抽取系统。Thomas et al.(2013)和Chowdhury and Lavelli(2013)提出了两阶段处理模型,首先检测出DDIs,然后将提取的DDIs分为四种类型。Thomas et
al.(2013)使用了几种核方法的集合,而Chowdhury和Lavelli(2013)提出了带有负实例滤波的混合核方法。除了我们的模型之外,所有后续模型都使用了反实例过滤。Kim et al.(2015)提出了一种基于两阶段支持向量机的方法,该方法采用了具有丰富特征的线性支持向量机,包括单词特征、词对、依赖关系、解析树结构和基于名词短语的约束特征。我们的模型不使用特征,而是使用CNN。
基于深度学习的模型最近主导了DDI提取任务。其中,基于CNN的模型被广泛使用,而rnn受到的关注较少。Liu等(2016)建立了基于cnn的词嵌入和词位置嵌入模型。Zhao et al.(2016)提出了句法CNN (SCNN),它利用句子的句法信息以及词性标签和依赖树的特征进行句法词嵌入。Liu等人(2016)利用多通道CNN (MCCNN)进行DDI提取,实现了多词嵌入的融合。我们的工作不同于他们,因为我们采用了一种注意机制
对于基于RNN的方法,Sahu和Anand(2017)提出了一种基于RNN的模型,命名为Joint AB-LSTM (Long - short Memory)。联合AB-LSTM由两个基于rnn的模型串联而成:双向LSTM (Bi-LSTM)和细心池化的Bi-LSTM。该模型在ddiextract -2013共享任务数据集上表现为最先进的性能。我们的模型是一个具有CNN和注意机制的单一模型,其性能与他们的模型相当,如表6所示。
Wang et al.(2016)提出了多级注意CNN,并将其应用于一般领域关系分类任务SemEval 2010 task 8 (Hendrickx et al., 2009)。他们的注意机制使宏观F1得分提高了1.9pp(从86.1%提高到88.0%),他们的模型在任务上取得了最先进的表现。 # 6. 结论 本文提出了一种新的DDIs提取注意机制。我们用softmax和ranking两种不同的目标函数建立了基于cnn的DDI抽取模型,并将注意力机制纳入模型中。我们在ddiextract -2013共享任务9.2任务上进行了测试,结果表明,注意机制和基于排名的目标函数都能有效提取ddi信息。当我们比较没有负实例过滤的性能时,我们的最终模型获得了69.12%的f分数,这与最先进的模型是竞争的。
原论文名称:Extracting Drug-Drug Interactions with Attention CNNs