A graph auto-encoder model for miRNA-disease associations prediction
本篇推文引自:A graph auto-encoder model for miRNA-disease associations prediction
1. 摘要
越来越多的证据表明miRNAs的异常表达参与了人类各种复杂疾病的进化和进展。将疾病相关的miRNAs作为新的生物标志物,可以促进疾病病理学和临床医学的发展。我们提出了一种新的图自动编码模型GAEMDA,用于端到端地识别miRNA疾病的潜在关联。具体地说,GAEMDA模型应用了基于图神经网络的编码器,它包含聚合函数和多层感知器,用于聚集节点的邻域信息,生成miRNA和疾病节点的低维嵌入,实现异构信息的有效融合。然后,将miRNA和疾病节点的嵌入输入双线性解码器,以识别miRNA与疾病节点之间的潜在联系。实验结果表明,在5倍交叉验证下,GAEMDA的曲线下面积平均为93.56±0.44%。此外,我们还对结肠肿瘤、食管肿瘤和肾脏肿瘤进行了病例研究。因此,在与这些疾病相关的前50个miRNAs预测中,有48个被人类癌症中差异表达的miRNAs和人类疾病数据库中的microRNA解除调控数据库所证实,令人满意的预测性能表明GAEMDA模型可以作为一个可靠的工具来指导miRNAs的调控作用的后续研究。此外,源代码可在https://github.com/chimianbuhetang/GAEMDA上找到。
2. 介绍
MicroRNAs是一种小的、内源性的、非编码的单链RNA分子,其长度约为22个核苷酸。越来越多的研究分析表明,miRNAs在细胞增殖、分化、信号转导、病毒感染等多种复杂生物学过程中发挥着关键作用。
计算方法可以为研究排名靠前的miRNAs提供一个新的视角,并促使他们进行相关的实验方法来进一步验证这些关联。在过去的十年中,已经提出了许多预测miRNA疾病关联的计算方法。在这些方法中,基于相似性度量的方法是一种经典的计算方法,它基于功能相似的mirna倾向于与表型相似的疾病相关的假设,对疾病相关的mirna进行排序。基于机器学习的方法是另一种常用的预测miRNA疾病相关性的计算方法。
受图神经网络在图结构数据数据集的巨大进展的影响,许多基于图神经网络的方法正在出现,以解决潜在的miRNA疾病关联的预测问题。在本文中,我们提出了一个新的图自动编码模型GAEMDA,用于预测miRNA疾病的潜在关联。具体来说,我们首先构造了miRNA和疾病二部图来描述miRNA与疾病之间的关联,其中每个节点用相应的相似性信息表示,每个连接代表相应的关联。其次,考虑到miRNA和疾病节点的异质性,设计了节点类型转换矩阵,将miRNA和疾病节点投影到同一向量空间中。第三,为了充分挖掘miRNA与疾病之间丰富的相互作用信息,我们通过基于图神经网络的编码器,将节点的异构邻域特征聚合到原始特征中,生成节点的嵌入。第四,将miRNA和疾病节点嵌入到双线性译码器中,重建miRNA节点与疾病节点之间的链接。然后利用交叉熵损失和反向传播算法对整个模型进行端到端的训练。此外,我们利用5倍交叉验证对GAEMDA模型的预测性能进行了评估。最后,GAEMDA的平均曲线下面积(AUC)为93.56±0.44%,准确度为84.93±0.95%,精密度为81.37±1.98%,召回率为90.70±1.27%,F1评分为85.75±0.76%。
3. 材料和方法
人类miRNA疾病协会
在本研究中,我们采用HMDD v2.0作为基准数据集,在383种疾病和495种miRNA之间,我们可以获得5430个实验证实的miRNA疾病关联。为了方便起见,我们使用了一个包含383行和495列的二进制矩阵DM来存储关联。如果疾病与miRNA相关,则矩阵DM对应位置的元素值设为1,否则为0。请注意,在我们接下来的实验中,所有实验验证的关联都被选为阳性样本。
miRNA功能相似性
在Wang等提供的miRNA功能相似性计算基础上,假设表型相似的疾病更可能与功能相似的miRNAs连锁,反之亦然,我们可以从https://www.cuilab.cn/files/images/cuilab/misim.zip。在这里,我们建立了495行495列的矩阵MFSM来存储miRNA功能相似性,其中MFSM(mi,mj)表示miRNA-mi和mj之间的miRNA功能相似性得分。
疾病语义相似性
基于先前的研究,疾病语义相似度可以根据医学主题词(MeSH)来计算,可在https://www.ncbi.nlm.nih.gov/。在这里,我们将每种疾病描述为有向无环图(DAG)。具体来说,我们可以采用DAG(di)=(di,T(di),E(di))来描述疾病di,其中T(di)表示由节点di及其祖先节点组成的一组节点,E(di)表示包含从父节点到子节点的直接链接的对应边集。然后,我们可以计算疾病dk对di的语义贡献如下: 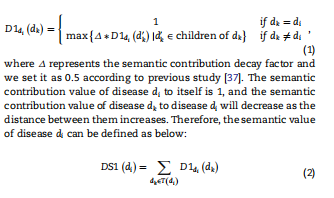 假设两种疾病在DAG中所占比例较大,可以认为两种疾病更相似,我们可以得到疾病di和dj之间的疾病语义相似度DSSM1(di,dj),如下所示:
假设两种疾病在DAG中所占比例较大,可以认为两种疾病更相似,我们可以得到疾病di和dj之间的疾病语义相似度DSSM1(di,dj),如下所示: 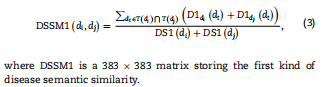 但是,考虑到出现在多个DAG中的疾病可能更常见,出现在较少DAG中的疾病可能更具体,因此同一层DAG中疾病的语义贡献值应该有所不同。因此,我们在前人研究的基础上,采用了另一种方法来计算疾病的语义相似度。这里,疾病dk对di的语义贡献可以描述如下:
但是,考虑到出现在多个DAG中的疾病可能更常见,出现在较少DAG中的疾病可能更具体,因此同一层DAG中疾病的语义贡献值应该有所不同。因此,我们在前人研究的基础上,采用了另一种方法来计算疾病的语义相似度。这里,疾病dk对di的语义贡献可以描述如下: 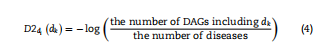 相应地,由式(5)得到疾病di的语义值,由式(6)得到疾病di与dj之间的疾病语义相似度DSSM2(di,dj)。
相应地,由式(5)得到疾病di的语义值,由式(6)得到疾病di与dj之间的疾病语义相似度DSSM2(di,dj)。 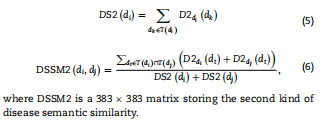 为了获得更合理的疾病语义相似度,我们在前人研究的基础上,综合这两种疾病的语义相似度,计算最终的疾病语义相似度。最后,根据下式得到疾病di与dj之间的疾病语义相似度DSSM(di,dj):
为了获得更合理的疾病语义相似度,我们在前人研究的基础上,综合这两种疾病的语义相似度,计算最终的疾病语义相似度。最后,根据下式得到疾病di与dj之间的疾病语义相似度DSSM(di,dj):
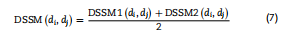 ## miRNAs与疾病的高斯相互作用轮廓核相似性 基于以往的研究,高斯相互作用轮廓核相似性可以通过假设相似的miRNAs更可能与相似的疾病相关。具体地说,一个位于矩阵DM第i列的二元向量IP(mi)被构造来表示miRNA与每种疾病之间的关联。然后,miRNAs-mi和mj之间的miRNAs-MGSM(mi,mj)的高斯相互作用轮廓核相似性可计算如下:
## miRNAs与疾病的高斯相互作用轮廓核相似性 基于以往的研究,高斯相互作用轮廓核相似性可以通过假设相似的miRNAs更可能与相似的疾病相关。具体地说,一个位于矩阵DM第i列的二元向量IP(mi)被构造来表示miRNA与每种疾病之间的关联。然后,miRNAs-mi和mj之间的miRNAs-MGSM(mi,mj)的高斯相互作用轮廓核相似性可计算如下:


miRNAs与疾病的综合相似性研究
考虑到得到的miRNA功能相似度矩阵和疾病语义相似度矩阵中存在大量稀疏值,我们将高斯交互轮廓核相似度引入miRNA和疾病相似度中矩阵。基于在Chen的研究[18]中,miRNA之间miRNAs IM(mi,mj)的综合相似性mi和mj按式(12)计算,疾病di和dj之间疾病ID(di,dj)的综合相似性计算公式(13)。
 ## GAEMDA GAEMDA可以描述为五个步骤(见图1):(i)构建miRNA疾病二分图,(ii)将miRNA和疾病节点投影到同一向量空间中,(iii)应用基于图神经网络的编码器生成miRNA和疾病节点的嵌入,(四)利用双线性译码器重构二部图中的链路,(五)应用交叉熵损失函数对整个模型进行端到端的训练。接下来,我们将讨论每个步骤的具体实现细节。
## GAEMDA GAEMDA可以描述为五个步骤(见图1):(i)构建miRNA疾病二分图,(ii)将miRNA和疾病节点投影到同一向量空间中,(iii)应用基于图神经网络的编码器生成miRNA和疾病节点的嵌入,(四)利用双线性译码器重构二部图中的链路,(五)应用交叉熵损失函数对整个模型进行端到端的训练。接下来,我们将讨论每个步骤的具体实现细节。
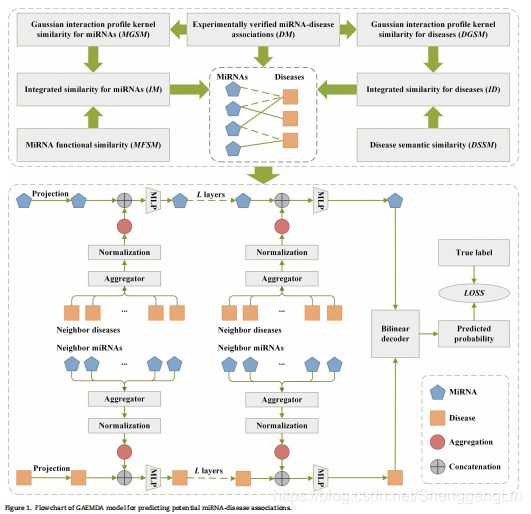 在第1步中,我们将多个数据源整合到一个包含495个miRNA节点和383个疾病节点的miRNA疾病二分图中。如我们所知,HMDD v2.0中总共有5430个实验验证的miRNA疾病关联。在这里,我们将所有5430个关联视为miRNA节点和疾病节点之间的阳性连接。此外,为了更好地训练模型,我们需要构造相等数量的阴性连接来平衡样本集。考虑到miRNAs与疾病之间的未知关联数量远大于已知关联的数量,我们从未知关联中随机选取5430个关联作为阴性关联,将它们作为阴性关联添加到miRNA疾病二部图中。然后,将所有的阳性链接标记为1,所有阴性链接标记为0,以进行后续的模型训练。此外,我们将miRNA与疾病的综合相似性分别视为miRNA特征和疾病特征。具体而言,miRNA-mi可以描述为495维向量 Fmi,如下所示:
在第1步中,我们将多个数据源整合到一个包含495个miRNA节点和383个疾病节点的miRNA疾病二分图中。如我们所知,HMDD v2.0中总共有5430个实验验证的miRNA疾病关联。在这里,我们将所有5430个关联视为miRNA节点和疾病节点之间的阳性连接。此外,为了更好地训练模型,我们需要构造相等数量的阴性连接来平衡样本集。考虑到miRNAs与疾病之间的未知关联数量远大于已知关联的数量,我们从未知关联中随机选取5430个关联作为阴性关联,将它们作为阴性关联添加到miRNA疾病二部图中。然后,将所有的阳性链接标记为1,所有阴性链接标记为0,以进行后续的模型训练。此外,我们将miRNA与疾病的综合相似性分别视为miRNA特征和疾病特征。具体而言,miRNA-mi可以描述为495维向量 Fmi,如下所示: 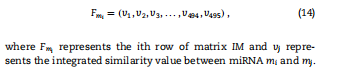 同样,疾病di可以描述为383维向量Fdi,如下所示:
同样,疾病di可以描述为383维向量Fdi,如下所示:

在第二步中,我们将异质性miRNA节点和疾病节点投影到同一向量空间中。由于miRNA疾病二部图中节点的异质性,在步骤1中miRNA节点和疾病节点属于不同的特征空间。为了便于后续计算,我们设计了节点类型转换矩阵,将miRNA节点和疾病节点的特征投影到同一向量空间中。miRNA节点的投影过程可以描述如下:


在第三步中,我们使用基于图神经网络的编码器生成miRNA和疾病节点的直接邻居信息的嵌入。例如,对于miRNA节点mi,我们首先计算其直接邻居特征的聚合,如下所示:  在第四步,我们采用双线性译码器来重建miRNA与疾病节点之间的链接。由于sigmoid激活函数在处理二值化分类问题上有很大的优势,我们在这里引入了一个双线性操作,然后使用一个sigmoid函数来预测miRNA节点mi与疾病节点dj链接的概率ˆyij,如下所示:
在第四步,我们采用双线性译码器来重建miRNA与疾病节点之间的链接。由于sigmoid激活函数在处理二值化分类问题上有很大的优势,我们在这里引入了一个双线性操作,然后使用一个sigmoid函数来预测miRNA节点mi与疾病节点dj链接的概率ˆyij,如下所示: 
4. 结果
实施细节和评估指标
我们在MXNet后端实现了基于深图库的GAEMDA模型。在训练阶段,我们用Xavier初始化随机初始化模型参数,用Adam[45]优化模型参数。此外,我们采用网格搜索法寻找最优超参数,并将学习率设为0.001,权值衰减为1e-3。为了避免过度拟合的问题,我们在投影操作和每个MLP层之后随机丢弃隐藏单元。我们在实验中从{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9}中寻找最佳的辍学率,并将其设为0.7。我们训练了1000个epoch的模型,并每10个epoch打印测试集结果。所有样本均基于HMDD v2.0构建。实验在Nvidia-Tesla-P100机群上进行。
GAEMDA与其他相关模型的比较
为了进一步证明模型的优越性,我们将GAEMDA模型与WBSMDA[18]、RFMDA[23]、PBMDA[46]、LLCMDA[47]、EDTMDA[48]、GBDT-LR[28]和MCLPMDA[49]七种最新模型的预测性能进行了比较。为了公平比较,以上模型均基于HMDD v2.0进行了5倍交叉验证[14]。另外,由于上述模型采用了多种不同的评价指标,因此本文仅利用AUC值来综合衡量这些模型的预测性能。请注意,所有的AUC值都是从他们论文中记录的最佳值中选出的。比较结果汇总在表3中,我们可以看到,我们的模型达到了这9个模型中最高的AUC值,比第二高的MCLPMDA模型高出0.36%,在Huang等人进行的基准测试中被证明是最高的预测模型。[50]。GAEMDA的优越性能得益于基于图神经网络的编码器和端到端的训练方式。 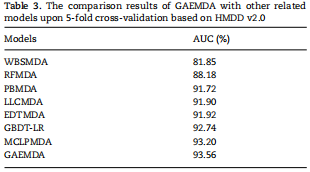 # 5. 结论
# 5. 结论
GAEMDA采用基于图神经网络的编码器生成miRNAs和疾病特征的嵌入,然后使用双线性解码器重建miRNAs与疾病之间的联系。此外,在5倍交叉验证下的多个评价指标以及对三种常见复杂疾病的案例研究均证明了GAEMDA的预测性能。因此,GAEMDA可以作为指导研究者研究相关miRNAs调控作用的有力工具。