MobileNet V2
今天介绍的是MobileNet V2.
介绍
从名字就可以知道,MobileNet V2是从V1的基础上进行改进的。对于MobileNet V1不太了解的读者不妨参照上周五的专栏。MobileNet v1为了适应移动端小算力的深度学习场景,提出了使用Depthwise卷积和Pointwise卷积来替代普通的卷积。
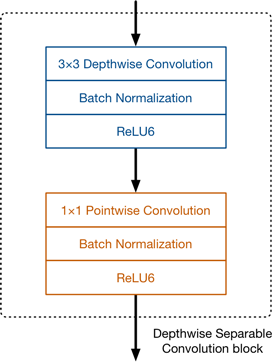
图1.在V1中一个常规的卷积被替换为上图中的模块。其中ReLU6函数是下限为0,上限为6的线性激活函数,这是为了避免在移动端,如果数值过大会产生精度损失。
在V2中,新的模块如下图所示:
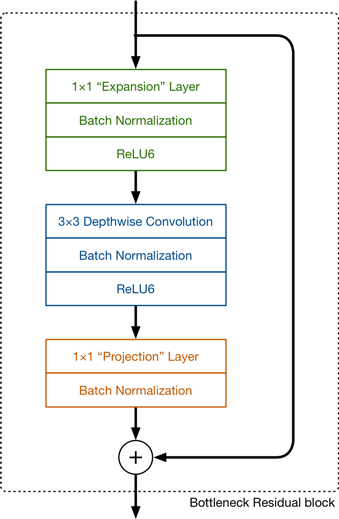
图2. V2中的卷积模块
创新点-模块设计
在图2中可以看到,V2保留了Depthwise卷积层,在其之前增加了“Expansion”层,在之后增加了“Projection”层。与V1的Pointwise convolution层相类似,新的两个层也是1×1卷积层。大家可以看到新的模块(Bottleneck Residual block)还增加了残差连接模块。
先介绍一下这两个新的层。Expansion层使用1×1卷积将低维特征映射到高维空间,交给Depthwise层进行处理,之后Projection层再对数据进行降维。
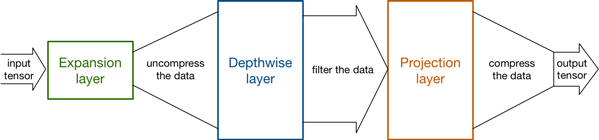
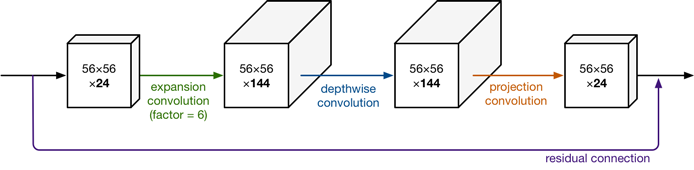
图3.Bottleneck Residual block的特征图大小
可以看到,模块的特征图大小两边窄中间宽,像个纺锤形,与ResNet的特征图结构恰好相反。这是怎么回事呢?ResNet中间窄可以减小卷积层的计算量,而对于MobileNet,考虑到Depthwise卷积的特性——一个特性图对应一个卷积核,如果想要提取出更多的信息,就要增多卷积核的数量,也就是要增大特征的维数。
查看图2我们可以发现,除了Projection层之外的组件最后都有激活层ReLU6,为何Projectin层没有呢?论文中使用了流形(manifold)的概念来解释这个问题。首先,流形学习的观点是:我们所能观察到的数据实际上是在高维空间中的低维流形。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上这些数据只要比较低的维度就能唯一的表示。所以直观上来讲,一个流形好比是一个d维的空间,在一个m维的空间中(𝑚>𝑑)被扭曲之后的结果。
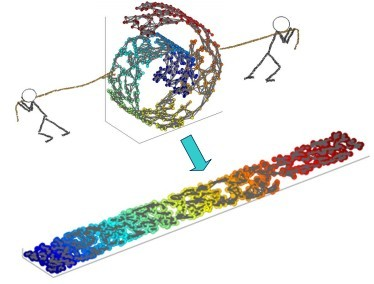
图4.“瑞士卷”。原始数据在3位空间中,通过学习流形,可以将其在二维空间表示。看上去就像是将一个瑞士卷拉平。
那这跟ReLU有什么关系呢?作者发现,如果当前激活空间内兴趣流形完整度较高,经过ReLU,可能会让激活空间坍塌,会不可避免地丢失信息。
图5.ReLU激活上限设为dim时,输出的流形
上图中可以看到,dim越大,保留的信息越完整。为了避免ReLU带来的损失,不妨使用线性映射来代替,因此最后的Projection层没有激活函数。
代码
来自https://github.com/weiaicunzai/pytorch-cifar100
1 | """mobilenetv2 in pytorch |
我们下次再见。