Variational Graph Auto-Encoders
本篇推文引自:Variational Graph Auto-Encoders
1. 图结构数据的隐变量模型:
本文提出了变分图自动编码器(VGAE),这是一种基于变分自动编码器(VAE)对图结构数据进行无监督学习的框架。这个模型利用潜在变量,能够学习无向图的可解释的潜在表示(见图1)。 
我们使用一个图形卷积网络(GCN)编码器和一个简单的内积解码器来演示这个模型。我们的模型在引文网络的链接预测任务上取得了有竞争力的结果。与现有的基于图结构数据的无监督学习模型和链路预测模型相比,我们的模型可以自然地融合节点特征,显著提高了对一些基准数据集的预测性能。
定义:给出一个无向、无权图G = (V, E),其中有N = |V|个节点。引入一个邻接矩阵G(假设对角元素设置为1,即每个节点连接到本身)及其程度矩阵D。进一步引入随机隐变量zi,将其归纳为N×F矩阵z。节点特征归纳为N×D矩阵X。
编码器:我们采用一个由两层GCN参数化的简单编码模型: 
解码器:解码器是由隐变量之间的内积给出的 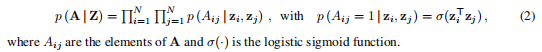
学习过程:  非概率图自动编码器(GAE)模型:对于VGAE模型的非概率变体,我们计算嵌入的Z和重建的邻接矩阵ˆ如下:
非概率图自动编码器(GAE)模型:对于VGAE模型的非概率变体,我们计算嵌入的Z和重建的邻接矩阵ˆ如下: 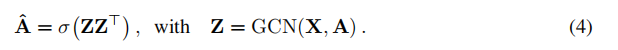
2. 在链接预测中的实验结果
我们演示了VGAE和GAE模型在几个流行的引文网络数据上的链接预测任务中学习有意义的潜在嵌入的能力。模型是在这些数据集的一个不完整版本上训练的,其中部分引文链接(边)已被删除,而所有节点特征保留。我们从之前删除的边缘和相同数量的随机采样的未连接节点(非边缘)对组成验证和测试集。
我们根据模型正确分类边缘和非边缘的能力来比较模型。验证集和测试集分别包含5%和10%的引用链接。验证集用于超参数的优化。我们比较了两个常用的基线:光谱聚类(SC)[5]和深度漫步(DW)[6]。SC和DW都提供节点嵌入z。我们使用Eq. 4(左图)计算重构邻接矩阵元素的分数。由于性能相似,我们忽略了DW[7,8]的最新变体。SC和DW都不支持输入特性。
对于VGAE和GAE,我们按照[9]中描述的那样初始化权重。我们使用Adam训练200次迭代,学习率为0.01。我们在所有实验中使用一个32-dim隐藏层和16-dim隐变量。对于SC,我们使用[11]的实现,嵌入维数为128。对于DW,我们使用了[8]作者提供的实现,并在他们的论文中使用了标准设置,即嵌入维数为128,每个节点长度为80的10个随机游走和上下文大小为10,只训练了一个epoch。
引文网络中链接预测任务的讨论结果如表1所示。GAE和VGAE表示不使用输入特性的实验,GAE和VGAE使用输入特性。我们报告了测试集中每个模型的ROC曲线下面积(AUC)和平均精度(AP)分数。数字显示了在固定数据集分割上随机初始化的10次运行的平均结果和标准误差。
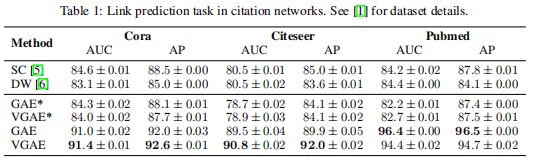 VGAE和GAE都在无特性的任务上实现了具有竞争力的结果。添加输入特性可以显著提高跨数据集的预测性能。与内积解码器结合使用高斯先验可能是一个糟糕的选择,因为内积解码器试图将嵌入从零中心推离(见图1)。然而,VGAE模型在Cora和Citeseer数据集上都实现了更高的预测性能。
VGAE和GAE都在无特性的任务上实现了具有竞争力的结果。添加输入特性可以显著提高跨数据集的预测性能。与内积解码器结合使用高斯先验可能是一个糟糕的选择,因为内积解码器试图将嵌入从零中心推离(见图1)。然而,VGAE模型在Cora和Citeseer数据集上都实现了更高的预测性能。
未来的工作将研究更适合的先验分布,更灵活的生成模型和应用随机梯度下降算法来改进可扩展性。
tensorflow实现:https://github.com/tkipf/gae pytorch实现:https://github.com/DaehanKim/vgae_pytorch