AlexNet
计算机视觉中那些经典的网络结构:AlexNet
虽说第一个典型的CNN pipeline是我们上次介绍的LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet。该网络结构是2012年ImageNet竞赛中取得冠军的网络模型,它的成功引起了大家对卷积神经网络的关注,此后CNN被广泛应用于计算机视觉领域。其网络结构也简单,适合初学者入门。
1.网络结构总览
AlexNet有6000万个参数和65000个 神经元,五层卷积,三层全连接网络,最终的输出层是1000通道的softmax层。
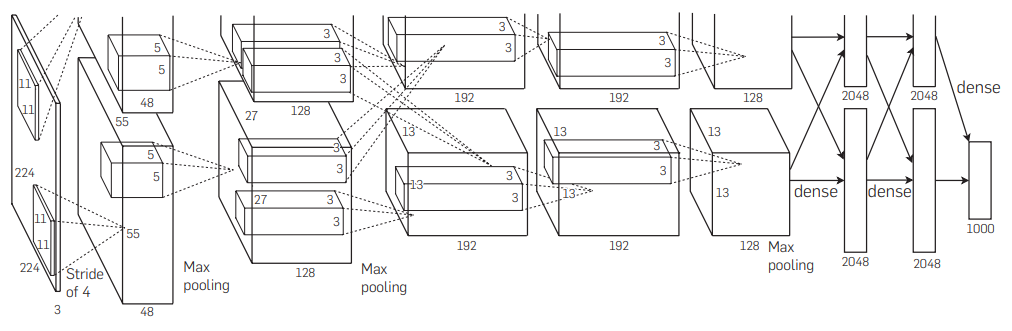
我们比照着上图pipeline来说明一下各个层。
第一层:卷积层1,输入为 224 × 224 × 3的图像,有96个卷积核。论文中为了提高训练速度,两片GPU分别计算48个核; 卷积核的大小为 11 × 11 × 3 ; stride = 4,pad = 0. 卷积后的图形大小,按照公式计算如下:
1 | wide = (224 + 2 * padding - kernel_size) / stride + 1 = 54 |
然后进行 局部响应归一化(Local Response Normalized), 后面跟着池化层pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的特征图
第二层:卷积层2, 输入为上一层卷积的feature map, 卷积的个数为256个,两个GPU分别计算128个卷积核。卷积核的大小为:5 × 5 × 48; pad = 2, stride = 1; 然后做 LRN, 最后 max_pooling, pool_size = (3, 3), stride = 2;
第三层:卷积3, 输入为第二层的输出,卷积核个数为384, kernel_size = (3 × 3 × 256 3 ×3×256), padding = 1, 第三层没有做LRN和Pool
第四层:卷积4, 输入为第三层的输出,卷积核个数为384, kernel_size = (3 × 3 3 ×3), padding = 1, 和第三层一样,没有进行LRN和Pool操作
第五层:卷积5, 输入为第四层的输出,卷积核个数为256, kernel_size = (3 × 3 3 ×3), padding = 1。然后直接进行max_pooling, pool_size = (3, 3), stride = 2;
第6,7,8层是全连接层,每一层的神经元的个数为4096,最终输出SoftMax为1000维,因为ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
2.一些细节
2.1损失函数Relu
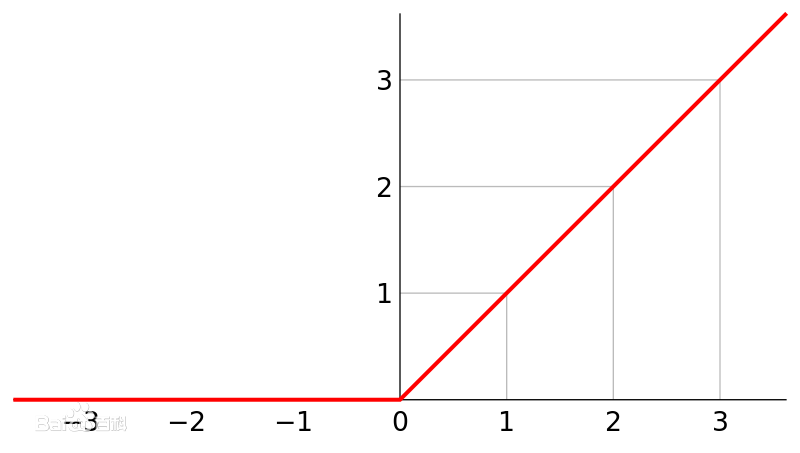
此前标准的L-P神经元的输出一般使用tanh或者是sigmoid作为计划函数,但是这些非线性函数在计算梯度时比较慢,而且在深度比较大的情况下可能导致梯度爆炸。使用Relu这样的非饱和线性函数训练时收敛更快。
2.2局部响应归一化(Local Response Normalization)
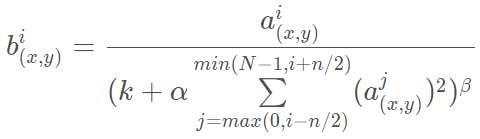
\(a^{i}_{(x,y)}\)表示ReLU在第i个kernel的(x, y)位置的输出,n表示的是其邻居的个数,N表示的是卷积核的总数量;\(b^{i}_{(x,y)}\)示的是LRN的结果,也就是ReLU输出的结果和它周围一定范围的邻居做一个局部的归一化。
不过后来VGG论文作者指出LRN用处不大,这都是后话了。
2.3覆盖池化(Overlapping Pooling)
一般的池化层因为没有重叠,所以pool_size 和 stride一般是相等的。如果 stride < pool_size, 那么就会产生覆盖的池化操作,使用覆盖的池化操作分别将top-1,和top-5的error rate降低了0.4%和0.3%。
3.代码实现
1 | import torch.nn as nn |