VGG
今天我们要介绍的网络结构是VGG网络。VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。因此,从图像中提取CNN特征,VGG模型是首选算法。
介绍
VGG由Oxford的Visual Geometry Group的组提出。VGG的主要特点是:
小卷积核。作者将卷积核全部替换为3x3卷积核。我们上次在介绍GoogLeNet的时候说过,可以用3×3的卷积核替代5×5,7×7的卷积核。
小池化核。相比AlexNet的3x3的池化核,VGG全部为更小的2x2的池化核;
层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
全连接换成卷积。网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
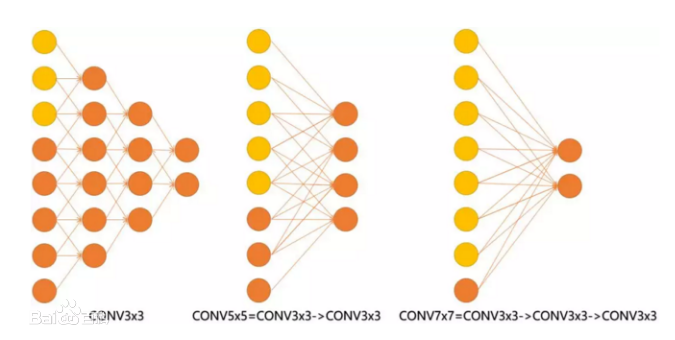
图1.用3×3卷积替换5×5卷积和7×7卷积
input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
整体架构
VGGNet的网络结构如下图所示。VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。
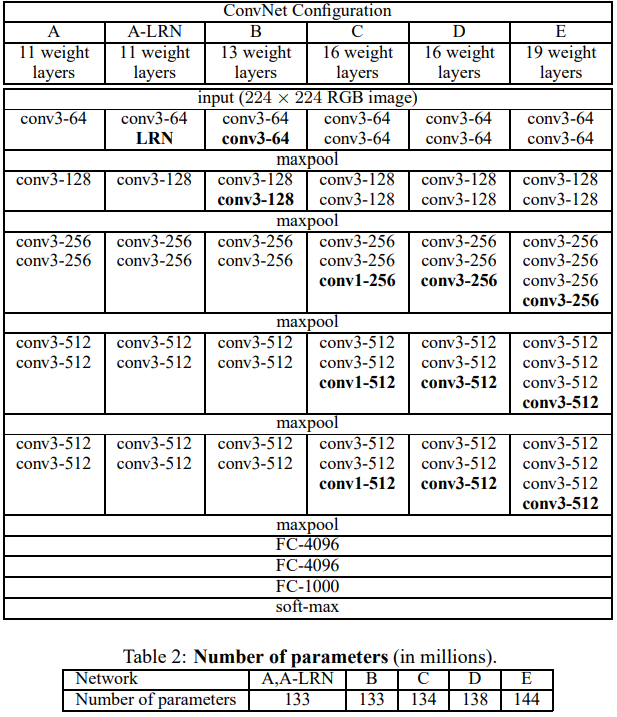
图2.VGG网络架构
VGGNet在训练的时候先训级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样收敛速度更快。VGGNet作者总结出LRN层作用不大,越深的网络效果越好,1×1的卷积也是很有效的,但是没有3×3的卷积效果好,因为3×3的网络可以学习到更大的空间特征。
网络在随层数递增的过程中,通过池化操作聚合局部信息,特征图的尺度随着每个池化操作缩小50%,5个池化l操作使得宽/高变化:224->112->56->28->14->7,同时网络通道的数量,随着5组卷积每次增大一倍:3->64->128->256->512->512。特征信息从一开始输入的224x224x3被变换到7x7x512,从原本较为local的信息逐渐分摊到不同channel上。
代码
代码来自https://github.com/weiaicunzai/pytorch-cifar100/
1 | """vgg in pytorch |