机器学习--支持向量机理论知识(一)
机器学习 | 支持向量机理论知识(一)
大家好,今天我们将要开始对于支持向量机的学习。
支持向量机(SVM)的全称是Support Vector Machine,其含义是支持向量运算的分类器,主要用于解决模式识别领域中的数据分类问题,属于有监督学习算法的一种。其中“机”的意思是机器,可以理解为分类器,或者一个算法 (在机器学习领域,常把一个算法看做一个机器);什么是支持向量呢?在求解的过程中,会发现只根据部分数据就可以确定分类器,这些部分数据称为支持向量。支持向量机要解决的问题可以用一个经典的二分类问题加以描述。下面我们用一个例子来说明。
问题:找到一条直线,分割两种颜色的点
新的问题:有很多条这样的直线,哪一条是最合适的呢?
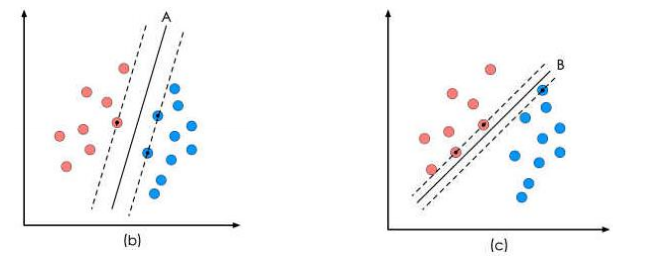
图b和c分别给出了A、B两种不同的分类方案,其中黑色实线为分界线,称为“决策面”。每个决策面对应了一个线性分类器。
解决方案:使得间隙最大的那条直线为最佳直线。
虽然目前来看,这两个分类器的分类结果是一样的,但如果考虑潜在的其它数据,则两者的分类性能是有差别的。SVM算法认为图1中的分类器A在性能上优于分类器B,其依据是A的分类间隔比B要大。
那么什么是分类间隔呢?
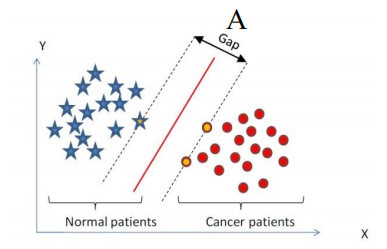
在保证决策面方向不变且不会出现错分样本的情况下移动决策面,会在原来的决策面两侧找到两个极限位置(越过该位置就会产生错分现象),如虚线所示。虚线的位置由决策面的方向和距离决策面最近的几个样本的位置决定。两条平行虚线正中间的分界线就是在保持当前决策面方向不变的前提下的最优决策面。两条虚线之间的垂直距离就是这个最优决策面对应的分类间隔。
什么是支持向量?
每一个可能把数据集正确分开的方向都有一个最优决策面,而不同方向的最优决策面的分类间隔通常是不同的,那个具有“最大间隔”的决策面就是SVM要寻找的最优解。而这个真正的最优解对应的两侧虚线所穿过的样本点,就是SVM中的支持样本点,称为“支持向量”。下图中,A决策面就是SVM寻找的最优解,而相应的三个位于虚线上的样本点在坐标系中对应的向量就叫做支持向量。
从表面上看,优化的对象是这个决策面的方向和位置。但实际上最优决策面的方向和位置完全取决于选择哪些样本作为支持向量。经过推导后可以发现,与线性决策面的方向和位置直接相关的参数都会被约减掉,最终结果只取决于样本点的选择结果。SVM算法要解决的是一个最优分类器的设计问题。首先需要讨论的就是如何把SVM变成用数学语言描述的最优化问题模型。
一个最优化问题通常有两个最基本的因素:
目标函数
优化对象
在线性SVM算法中,目标函数显然就是那个“分类间隔”,而优化对象则是决策面。所以要对SVM问题进行数学建模,首先要对上述两个对象(“分类间隔”和“决策面”)进行数学描述。
下周我们将用数学来细致地讲解支持向量机模型,谢谢大家的阅读!