机器学习--最大熵模型学习的最优化算法(一)
机器学习 | 最大熵模型学习的最优化算法(一)
今天我们来说最大熵模型学习中用到的最优化算法:改进的迭代尺度法。
我们知道最大熵的模型为: \[ P_w(y | x) = \frac{1}{Z_w(x)}exp(\sum^{n}_{i}w_if_i(x,y)) \] 其中: \[ Z_w(x) =\sum_{y}exp(\sum^n_{i}w_if_i(x,y)) \] 对数似然函数为: \[ L(\omega) = \sum_{x,y}\tilde P(x,y)\sum_{i=1}^nw_if_i(x,y)-\sum_x\tilde P(x)logZ_w(x) \] 目标是通过极大似然估计学习模型参数求对数似然函数的极大值\(\hat \omega\)。
改进的迭代尺度法的想法是:假设最大熵模型最大熵模型当前的参数向量是\(\omega\),找到一个新的参数向量\(\omega + \delta\),使模型的对数似然函数值增大。如果能有这样一种参数向量更新的方法 \(\omega \longrightarrow \omega + \delta\),那么就可以不停迭代,直至找到对数似然函数的最大值。
因为: \[ P_w(y | x) = \frac{1}{Z_w(x)}exp(\sum^{n}_{i}w_if_i(x,y)) \] 所以: \[ L(\omega + \delta) - L(\omega) = \sum_{x,y}logP_{\omega + \delta}(y|x)-\sum_{x,y}logP_{\omega }(y|x) \\ =\sum_{x,y}\tilde P(x,y)\sum^n_{i=1}\delta_if_i(x,y)-\sum_x\tilde P(x)log\frac{Z_{\omega+\delta}(x)}{Z_\omega(x)} \] 利用不等式\(-log\alpha \ge 1-\alpha,\alpha >0\)可知: \[ L(\omega + \delta) - L(\omega) \ge\sum_{x,y}\tilde P(x,y)\sum^n_{i=1}\delta_if_i(x,y) +\sum_x\tilde P(x)(1-\frac{Z_{\omega+\delta}(x)}{Z_\omega(x)})\\=\sum_{x,y}\tilde P(x,y)\sum^n_{i=1}\delta_if_i(x,y) + 1-\sum_x\tilde P(x)\frac{Z_{\omega+\delta}(x)}{Z_\omega(x)} \] 又知\(Z_w(x) =\sum_{y}exp(\sum^n_{i}w_if_i(x,y))\):
则 \[ \frac{Z_{\omega+\delta}(x)}{Z_\omega(x)} = \sum_y\frac{1}{Z_\omega(x)}(exp\sum^n_{i=1}\omega_if_i(x,y)×exp\sum^n_{i=1}\delta_if_i(x,y)) \] 又因为\(P_w(y | x) = \frac{1}{Z_w(x)}exp(\sum^{n}_{i}w_if_i(x,y))\): \[ \frac{Z_{\omega+\delta}(x)}{Z_\omega(x)} =\sum_yP_\omega(y|x)×exp\sum^n_{i=1}\delta_if_i(x,y) \] 于是: \[ L(\omega + \delta) - L(\omega) \ge\sum_{x,y}\tilde P(x,y)\sum^n_{i=1}\delta_if_i(x,y) + 1-\sum_x\tilde P(x)\frac{Z_{\omega+\delta}(x)}{Z_\omega(x)} \\ =\sum_{x,y}\tilde P(x,y)\sum^n_{i=1}\delta_if_i(x,y) + 1-\sum_x\tilde P(x)\sum_yP_\omega(y|x)×exp\sum^n_{i=1}\delta_if_i(x,y) \] 这里,将等式右端记为\(A(\delta|\omega)\),这是似然函数的下界。
如果我们能够找到适当的\(\delta\)使下界提高,那么似然函数也会随之提高。但\(\delta\)是一个向量,不易同时对每个方向都进行优化,于是固定其它方向,仅优化其中的一个方向,这时我们需要再一次更新下界,使得可以仅优化一个方向。
具体的,我们引入一个量:
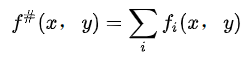
这个值表示所有特征在(x, y)中出现的次数,其可能为常数也可能不为常数。原因如下:
首先这个函数\(f\)本身代表的是一个规则,即\(x\)与\(y\)满足某一事实,则为1,否则为0。括号内的\(x\)和\(y\)是输入值,即每一个数据点的数据,或者说是每一个实例的数据。
那么\(f_i(x, y)\)中的下标i表示的是不同的规则,比如\(f_1(x, y)\)在x=1, y=2的情况下为1,否则为0;\(f_2(x, y)\)在x=2,y=2的情况下为1,否则为0。
对某一个实例而言,我们将其代入\(f_1\)和\(f_2\)中,判断这个实例的数据是否符合\(f_1\)和\(f_2\)的规则,如果仅符合\(f_1\)而不符合\(f2\),\(f1=1,f2=0\)。
那么\(\sum f_i(x,y)\)实际上是对一个特定的实例的数据进行i次不同规则的判断,这就是其即可能为常数也可能不为常数的原因。在常数的情况下,说明每一个实例的数据符合的规则的数量是一样的,比如有三个规则,实例1符合规则1和规则2,实例2符合规则2和规则3,实例3符合规则1和规则3,尽管它们符合的规则不同,但数量相同,三个实例的f#(x, y)都为2。当然,f#(x, y)为常数的情况发生的概率很小,因此f#(x, y)在大部分情况下都不是常数。
回到算法本身,定义了f#(x, y)之后,可以将\(A(\delta|\omega)\)进行改写,于是,最终得到了:
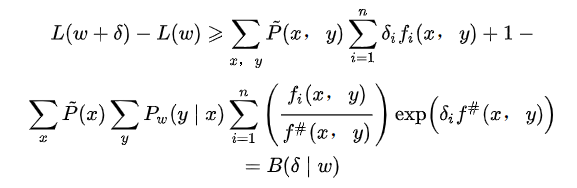
于是下界被再一次刷新,此时可以对向量\(\delta\)中的一个方向单独进行优化(求导)了。对其求偏导并令导数为0:
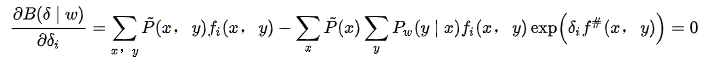
于是有:
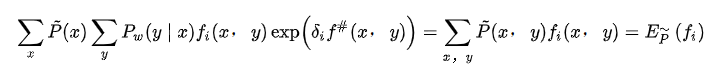
这样就可以依次对每一个\(\delta_i\)求解,得到向量\(\delta\)并对\(\omega\)进行更新迭代。
以上就是今天的内容,谢谢大家的观看!