final_keras
畅游人工智能之海--Keras教程之Sequential模型篇
各位读者大家好,今天我们就要开始正式地进行Keras的学习了。相信大家都读过了Keras的知识结构那篇文章,我们把Keras的模型讲解放在了最前面。这样布局是为了让大家先对Keras实现神经网络的整体架构了然于胸,在之后的学习中便可以找到其他的零碎知识点在框架中的位置,更有利于大家对Keras的学习。废话不多说,下面我们就开始吧!
Sequential模型,顾名思义,它是一个线性模型,即多个网络层进行线性堆叠构成Sequential模型。Sequential模型的构造方法有两种:一种是将网络层实例的列表传递给Sequential的构造器来创建一个Sequential模型;另一种是使用.add()方法将各层添加到模型中。
1 | #方法一 |
这样,一个简单的模型就搭好了。但是这样的模型是没有经过训练的,无法完成我们想要的功能。若是想对模型进行训练,我们还需要选择优化器、loss函数、评估标准等,使用compile方法对模型进行配置。之后才能使用训练数据对模型进行训练。
在这之前,模型需要知道它所期望的输入的尺寸(只需要告诉第一层输入尺寸信息,之后的层会自行推导。有以下几种方法完成这一任务:①使用input_shape参数传递给第一层,它是一个表示尺寸的元组;②某些2D层支持通过参数input_dim输入尺寸,某些3D时序层支持input_dim和input_length参数。如果想要为输入指定固定的batch大小,可以传递batch_size参数给一个层。下面两行代码是等价的。
1 | model.add(Dense(32, input_shape=(784,))) |
上面提到,我们在训练模型之前需要用compile方法对学习过程进行配置,基本的代码如下:
1 | model.compile(optimizer='rmsprop', |
optimizer就是优化器,loss就是损失函数,metrics就是评估标准。通过输入等号后面的内容可以针对不同的训练任务进行不同的选择。
在完成配置过程之后,我们便可以用fit方法对模型进行训练。代码如下:
1 | model.fit(data, labels, epochs=10, batch_size=32) |
其中data就是训练集,labels是对应的标签,epochs是训练轮数,batch_size是批大小。
除了上面提到的这些,Sequential模型还有一些其他的API(具体参数含义可以查看Keras文档):
1 | #根据名称(唯一)或索引值查找网络层,如果同时提供了 name 和 index,则 index 将优先。 |
接下来,我们来结合一个实例来梳理一下Sequential模型整体流程,以基于多层感知器的二分类为例。
1 | import numpy as np |
以上就是一个基本流程,关键点在注释里标注。
接下来大家会想,我们辛辛苦苦训练好了一个模型难道程序结束就没有了么?所以我们要采取一些方法保留模型,Keras提供了一些方法。
最完整的保存方法为model.save(filepath),这个方法将Keras模型保存到单个HDF5文件中,该文件包括:模型的结构,允许重新创建模型;模型的权重;训练配置项(损失函数,优化器);优化器状态,允许准确地从你上次结束的地方继续训练。之后还可以使用keras.models.load_model(filepath)重新实例化模型。还有只保存或加载模型的结构的方法:model.to_json(),model.to_yaml();model_from_json(json_string),model_from_yaml(yaml_string)。还有只保存或加载模型的权重的方法:model.save_weights(filepath);model.load_weights(filepath)
相信如果你能掌握这篇文章的内容,就可以自行构造一个Sequential模型啦!关于优化器等等关键参数的选择背后也有很深的学问,这关系到大家处理具体问题时的选择,希望大家在这篇文章之外多多去探索他们背后的学问,一起加油吧!
Model模型
用Sequential只能定义一些简单的模型,如果你想要定义多输入、多输出以及共享网络层,就需要使用Model模型了。
声明方法
1 | inputs = Input(shape=(784,)) |
在model模型的声明中,需要使用\(y = layer(...)(x)\)这样的格式来构建没一个层次,并在构造函数中声明你的模型的输入和输出是什么。
多输入多输出
来考虑下面的模型。我们试图预测 Twitter 上的一条新闻标题有多少转发和点赞数。模型的主要输入将是新闻标题本身,即一系列词语,但是为了增添趣味,我们的模型还添加了其他的辅助输入来接收额外的数据,例如新闻标题的发布的时间等。 该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。
模型结构如下图所示:
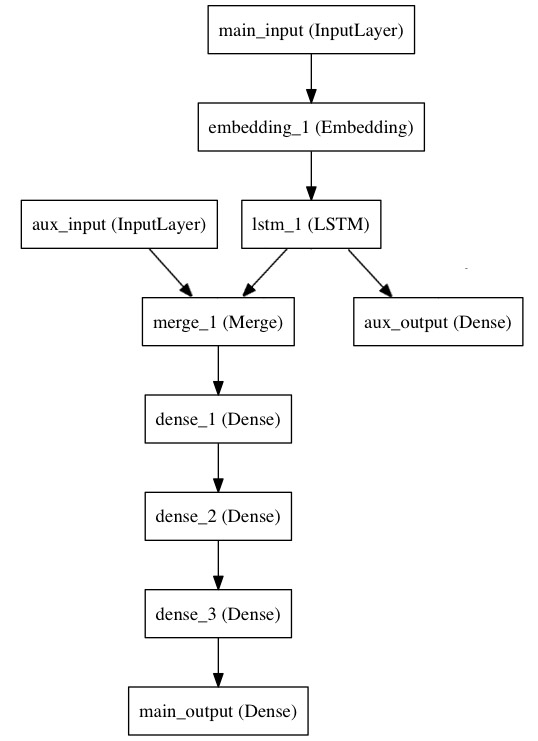
1 | from keras.layers import Input, Embedding, LSTM, Dense |
1 | auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out) |
1 | auxiliary_input = Input(shape=(5,), name='aux_input') |
1 | model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output]) |
共享网络层
多输入依赖于共享,直接看例子。
1 | import keras |
要在不同的输入上共享同一个层,只需实例化该层一次,然后根据需要传入你想要的输入即可:
1 | shared_lstm = LSTM(64) |
总结
在Model模型中,多输入、多输出、共享的实现都是简单的,只要按照一定的逻辑创建好有向图即可!
关于本文内容,部分借鉴自keras文档。
实验代码见https://github.com/1173710224/keras-cnn-captcha.git的model-example分支。
核心网络层(一)
各位读者大家好,上周我们已经详细讲解了Keras的两种模型,相信大家经过学习已经对Keras构建神经网络的两种方式有了一个清晰的认识。那么明确了网络结构之后,我们该选择什么网络层添加进神经网络里面呢?这就需要我们对网络层的作用进行细致的学习了。我们计划从这周开始进入对网络层的学习当中,那么今天,笔者便要向大家详细的介绍核心网络层的类别及功能,让我们一起学习吧!
Dense层
1 | keras.layers.Dense( |
作用:
将输入的特征在Dense层中经过非线性变化,提取这些特征之间的关联,最后映射到输出空间上,减少特征位置对分类带来的影响。实现的操作为:output = activation(dot(input, kernel) + bias) ,其中 activation 是按逐个元素计算的激活函数,kernel 是由网络层创建的权值矩阵,以及 bias 是其创建的偏置向量 (只在 use_bias 为 True 时才有用)。如果输入的秩大于2,那么输入首先被展平然后再计算与kernel 的点乘
输入尺寸:nD张量,当使用Dense层作为第一层时,使用input_shape(整数元组)指定输入大小。
输出尺寸:nD张量,输出尺寸为(batch_size,units)
例子:
1 | #Dense不作为第一层时无需input_shape参数 |
Activation层
1 | keras.layers.Activation( |
功能:对输入应用激活函数并输出
输入尺寸:任意大小,当使用Activation层作为第一层时,使用input_shape(整数元组)指定输入大小。
输出尺寸:与输入相同。
例子:
1 | #使用tanh激活函数 |
Dropout层
1 | keras.layers.Dropout( |
功能:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,将输入单元的值按比率随机设置为 0,有效防止过拟合。
输入大小:任意大小。
输出大小:与输入一致。
例子:
1 | #将输入单元的值按0.02的概率设置为0 |
Flatten层
1 | keras.layers.Flatten( |
功能:把输入展平成一维化输出,常用在从卷积层到全连接层的过渡,不影响batch的大小。
输入:任意尺寸。
输出:将输入尺寸的各维大小相乘得到的值即为输出尺寸。
例子:
1 | # 一开始的输入尺寸为(None, 64, 32, 32) |
Input层
1 | keras.engine.input_layer.Input() |
功能:实例化Keras张量,一般用于网络的第一次
输入尺寸:任意大小,用于第一层时参数为shape,指定输入尺寸。
输出尺寸:跟输入尺寸一致。
例子:
1 | #实例化一个Keras张量,一般用于构建Model类模型 |
Reshape层
1 | keras.layers.Reshape( |
功能:根据给定的参数将输入调整为指定的尺寸
输入尺寸:任意大小,当使用Reshape层作为第一层时,使用input_shape(整数元组)指定输入大小。
输出尺寸:(batch_size,) + 指定的尺寸。
例子:
1 | #不是第一层时无需导入input_shape=() |
Permute层
1 | keras.layers.Permute( |
功能:根据给定的参数置换输入的维度,在某些场景下很有用,例如将RNN和CNN连接在一起。
输入尺寸:任意大小,当使用Permute层作为第一层时,使用input_shape(整数元组)指定输入大小。
输出尺寸:(batch_size,)+输入尺寸经过指定置换后的尺寸。
例子:
1 | #可以看到置换模式为把输入的第一维和第二维进行置换 |
相信大家经过今天的学习,能够对核心网络层的一部分的类型和功能有一个清晰的认知,明天的文章将带领大家一起学习核心网络层剩下的部分,让我们一起期待吧!
核心网络层(二)
RepeatVector
keras.layers.RepeatVector(n)
将该层的输入重复n次
将二维的输入变成三维的,形式化的表述就是\((None,features) -> (None,n,features)\)
1 | model = Sequential() |
Lambda
- keras.layers.Lambda(function, output_shape=None, mask=None, arguments=None)
- 将一个表达式包装为layer对象
1 | model.add(Lambda(lambda x: x ** 2)) # 添加了一个层,将所有的x变成x^2 |
常用的参数就是前两个,第一个指定要对输入进行什么样的操作,第二个对输出的shape进行检查
可以支持任何类型的输入,但是如果是model的第一层需要指定input_shape
ActivityRegularization
- L1和L2正则化能够有效地避免过拟合,keras将这两个正则化封装在了这个层中(ps:关于两个正则化,可以到 https://www.jianshu.com/p/c9bb6f89cfcc 这个博客学习)
- keras.layers.ActivityRegularization(l1=0.0, l2=0.0)
- 该层的输入输出的维度相同,因为正则化不影响维度
Masking
将训练数据中的某些值跳过
一个官方给出的例子是:
- 考虑一组将要传给LSTM的数据
(samples, timesteps, features)。 - set
x[0, 3, :] = 0.andx[2, 5, :] = 0. - 并将这个
mask_value=0.的Masking层插入到LSTM之前
- 考虑一组将要传给LSTM的数据
1 | model = Sequential() |
SpatialDropout1(2)(3)D
- 原理与dropout相同
- 官方给出的解释是,在此版本中,三个layer的作用与dropout相同,都是以一定的概率保持连接
基础卷积层
本讲提要
这次结合代码跟大家分享四种卷积:一维卷积,二维卷积,以及基于它们的可分离卷积。
一维卷积
keras接口
1 | keras.layers.Conv1D(filters, kernel_size, strides=1, padding='valid', data_format='channels_last', dilation_rate=1, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) |
其中的regularizer和constraint会在后面进行详细讲解,可以先不用
一维卷积的过程
1 | layers.Conv1D(filters=2, kernel_size=4, use_bias=False) |
以上面这个卷积层为例,它的工作过程如下:
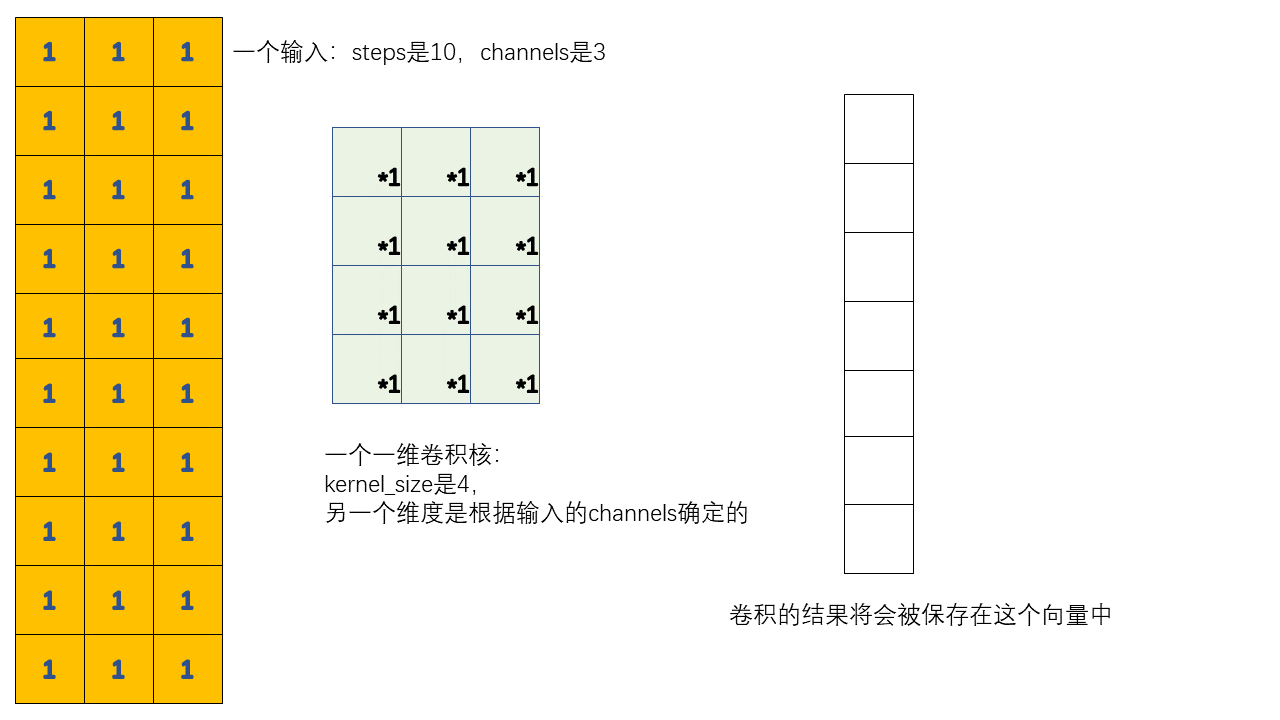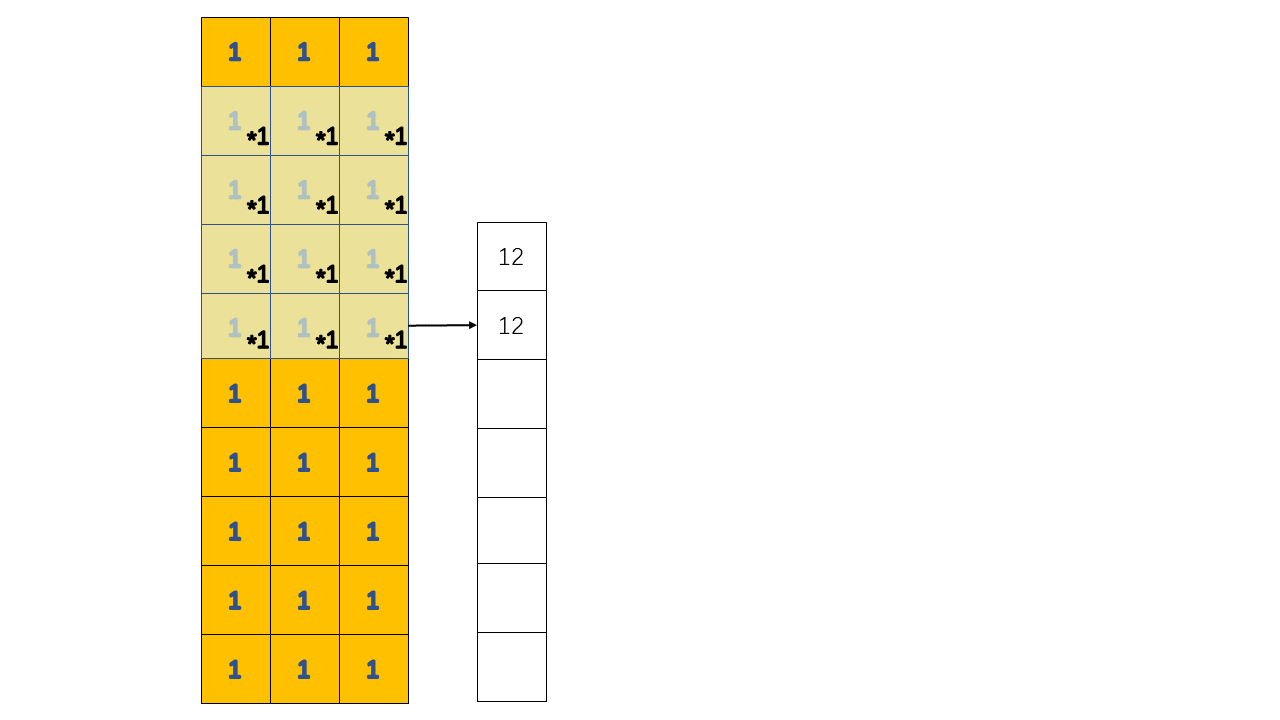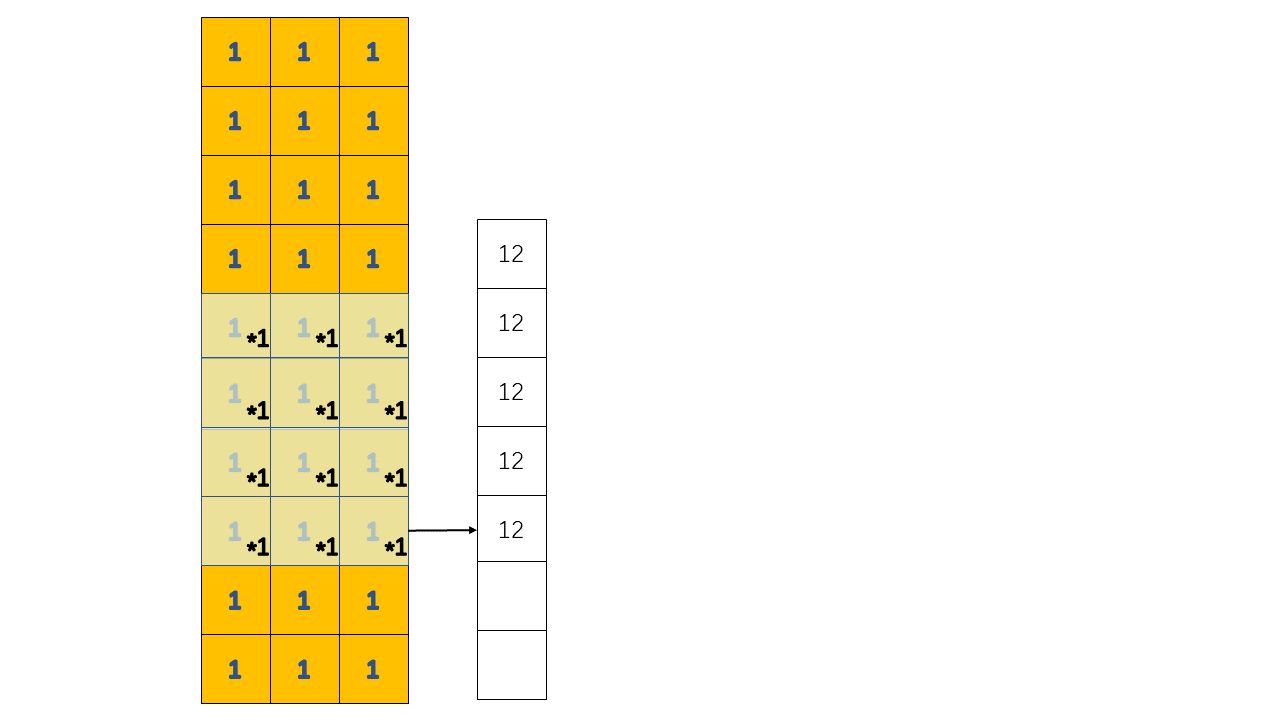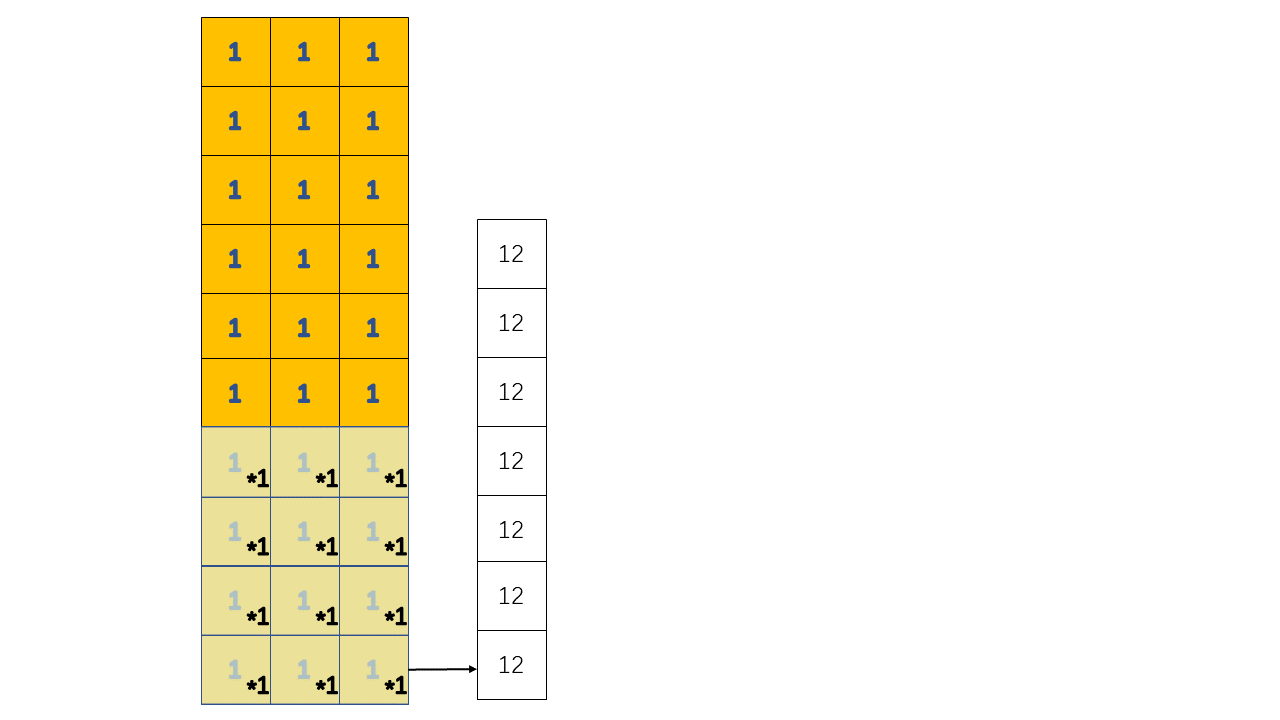
在这个例子中,我们对一个全1的输入进行卷积操作,如图中所示的操作应该进行两次,因为我们指定的filters = 2
所以输入和输出的shape应该是
1 | Layer (type) Output Shape Param # |
其它参数的含义
strides 指的是卷积核每次滑动的长度,图中卷积核每次滑动一格,默认值是1
padding 指是不是要对结果进行扩充,它的默认取值是‘valid’,默认情况下不产生任何变化,还可以取'causal'和'same',以增强对边缘数据的特征提取,处理之后的shape如下所示
1
2
3
4
5
6
7_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 10, 3) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 10, 2) 24
=================================================================data_format 没什么用,直接用默认值就行了,这个变量是在规定每个输入的含义,它有两个取值’channels_last‘和’channels_first‘,默认是第一个,也就是默认的输入是 (batch, steps, channels) 这样的,而第二个种对应的输入应该是 (batch, channels, steps) 这样的。
dilation_rate 会对卷积核进行扩充,但是不改变原始的卷积核
二维卷积
keras接口
1 | keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) |
与一维相比发生的变化
input 单条数据从二维变成三维,如图所示展示的是一个3通道(上下)的二维数据

kernel_size 应该是一个二元组,这个二元组指的是在一个通道内对数据的卷积
可分离卷积
keras接口
1 | keras.layers.SeparableConv1D(filters, kernel_size, strides=1, padding='valid', data_format='channels_last', dilation_rate=1, depth_multiplier=1, activation=None, use_bias=True, depthwise_initializer='glorot_uniform', pointwise_initializer='glorot_uniform', bias_initializer='zeros', depthwise_regularizer=None, pointwise_regularizer=None, bias_regularizer=None, activity_regularizer=None, depthwise_constraint=None, pointwise_constraint=None, bias_constraint=None)# 这是一维的接口,二维的类似,就不占位置了 |
发生的变化
用不同的卷积核在各个通道上进行卷积,然后再用一个卷积核将不同的通道合并
depth_multiplier 可以把一个通道卷积之后的结果变成多个通道,其实也就是多次卷积,但是需要注意的是整个卷积层最后输出的shape不变
depthwise
keras接口
1 | keras.layers.DepthwiseConv2D(kernel_size, strides=(1, 1), padding='valid', depth_multiplier=1, data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, depthwise_initializer='glorot_uniform', bias_initializer='zeros', depthwise_regularizer=None, bias_regularizer=None, activity_regularizer=None, depthwise_constraint=None, bias_constraint=None) |
解释
其实就是可分离卷积的第一步,keras的制作者把它单独提出来做成了一个接口
ending
卷积层还有几个操作,下周二分析
在这里附上实验代码
1 | from keras import layers |
三维卷积
本讲提要
接着上次的内容,继续说说keras的卷积
- 三维卷积Conv3D
- 转置卷积ConvTranspose
- 裁剪层Cropping
- 零填充层ZeroPadding
Conv3D
1 | keras.layers.Conv3D(filters, kernel_size, strides=(1, 1, 1), padding='valid', data_format=None, dilation_rate=(1, 1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) |
不同维数的卷积区别在于输入层、卷积核以及输出层的维数不同。
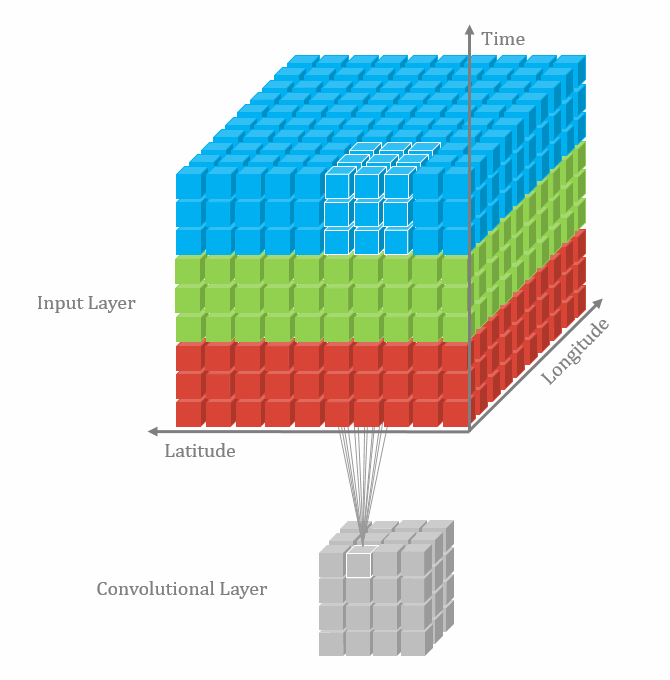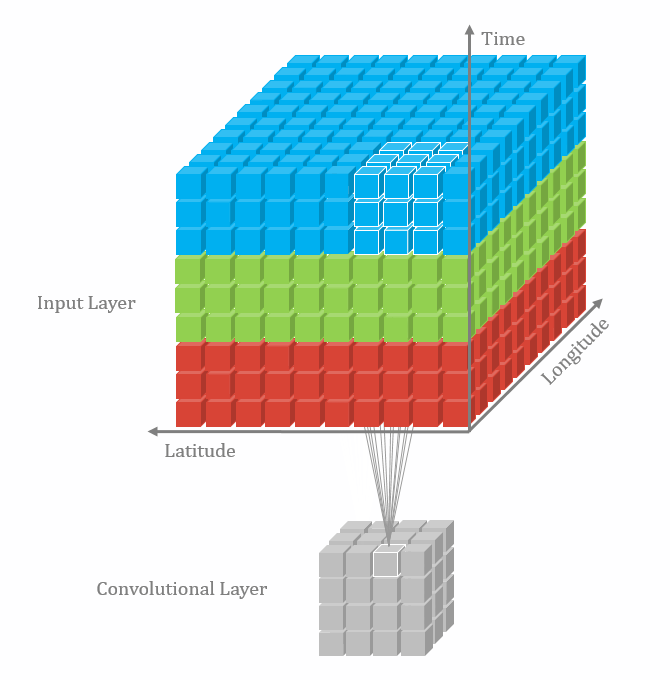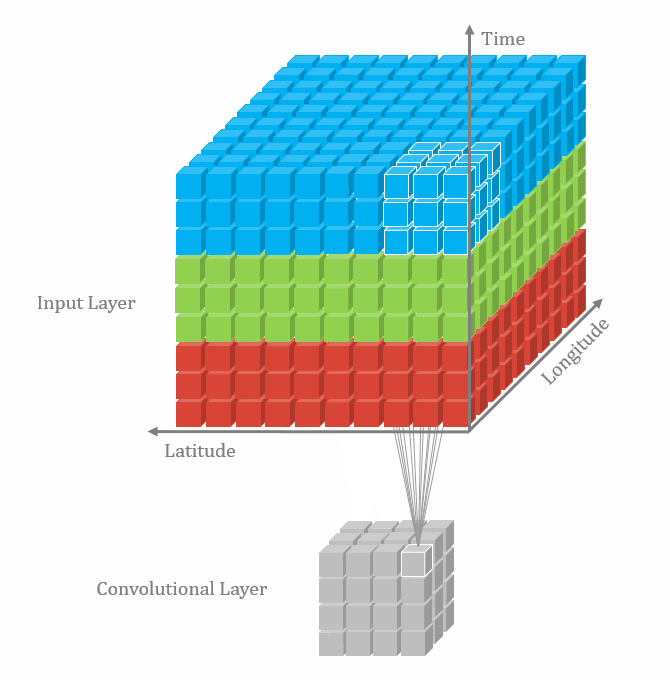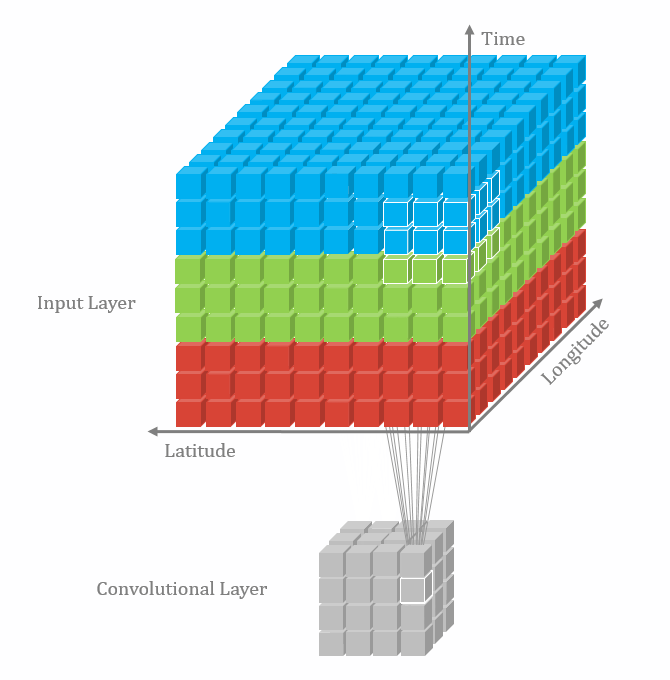
图1 三维卷积[1]
转置卷积
对转置卷积的需求通常来自于使用与普通卷积相反方向的转换的愿望,即,从具有某些卷积输出形状的东西到具有其输入形状的东西,同时保持与上述卷积兼容的连接模式。可以简单地理解为把卷积结果还原成卷积前的矩阵。
转置卷积也被称为分数步长卷积,下图是一个stride = 1/2 的示意图,蓝色部分是输入,蓝绿色矩阵是输出,灰色是卷积核。
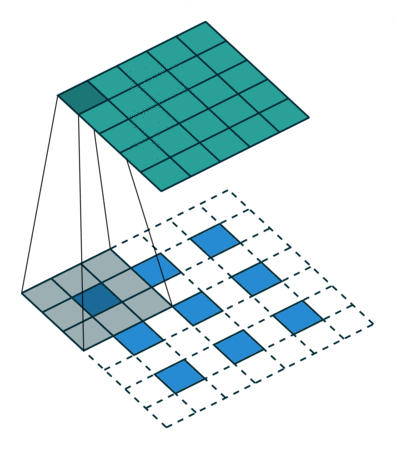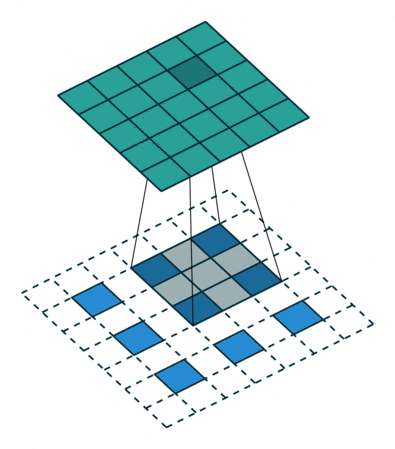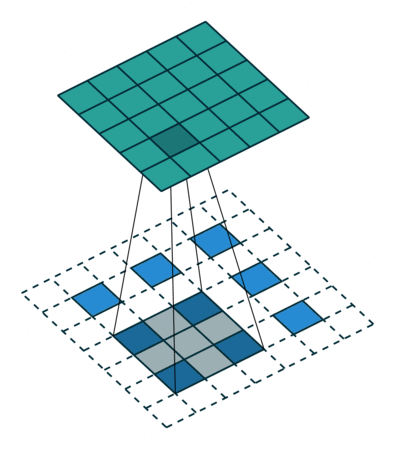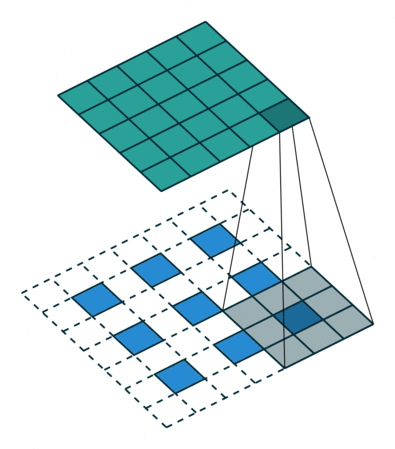
图二 Conv2DTranspose with padding,stride[2]
1 | keras.layers.Conv2DTranspose(filters, kernel_size, strides=(1, 1), padding='valid', output_padding=None, data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) |
裁剪层
对输入做裁剪的层
1 | Cropping2D:keras.layers.Cropping2D(cropping=((0, 0), (0, 0)), data_format=None) |
cropping后的两个tuple被解释为: ((top_crop, bottom_crop), (left_crop, right_crop))
上采样层
上采样指的是任何可以让图像变成更高分辨率的技术。UpSampling2D可以看作是Pooling的反向操作,就是采用最近邻插值来对图像进行放大。upsampling2D可用于应对一些需要大尺寸图片来作为输入的任务,比如GAN对抗网络。
UpSampling2D
1 | keras.layers.UpSampling2D(size=(2, 2), data_format=None, interpolation='nearest') |
##零填充层
ZeroPadding用于为矩阵周围填充0
1 | keras.layers.ZeroPadding2D(padding=(1, 1), data_format=None) |
2D 输入的零填充层(例如图像)。该层可以在图像张量的顶部、底部、左侧和右侧添加零表示的行和列。
[1]三维卷积: http://inhi.kim/archives/1146
[2]转置卷积: https://github.com/vdumoulin/conv_arithmetic
循环神经网络(一)
RNN是啥?
循环神经网络是具有内部存储器的前馈神经网络的概括。RNN本质上是递归的,因为它对数据的每个输入执行相同的操作,而当前输入的输出取决于过去的一次计算。产生输出后,将其复制并发送回循环网络。为了做出决定,它会考虑当前输入和从先前输入中学到的输出,具体的过程如图所示。 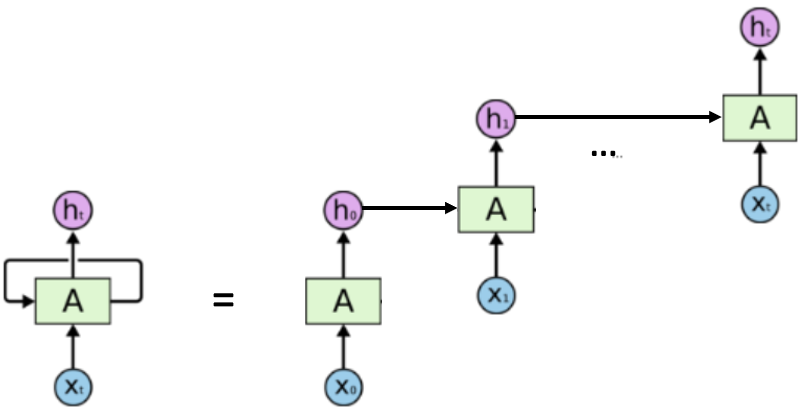 对应的计算公式可以表述为: \[
h_t = f(h_{t - 1},x_t)
\] 从计算公式中我们也能够看到,循环神经网络被开发的意义所在。一个具体的例子(加了激活函数和神经网络参数)就是: \[
h_t = tanh(W_{h} \cdot h_{t - 1} + W_x \cdot x_t)
\]
对应的计算公式可以表述为: \[
h_t = f(h_{t - 1},x_t)
\] 从计算公式中我们也能够看到,循环神经网络被开发的意义所在。一个具体的例子(加了激活函数和神经网络参数)就是: \[
h_t = tanh(W_{h} \cdot h_{t - 1} + W_x \cdot x_t)
\]
pros and cons
- RNN可以对数据序列进行建模,因此可以假定每个样本都依赖于先前的样本
- 循环多了长期的知识就循环没了(梯度消失)
keras 实现
SimpleRNN
1 | keras.layers.SimpleRNN(units, activation='tanh', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False) |
units:输出维度。
dropout: dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,如图所示。在这里就是一个概率值,取值[0,1]。
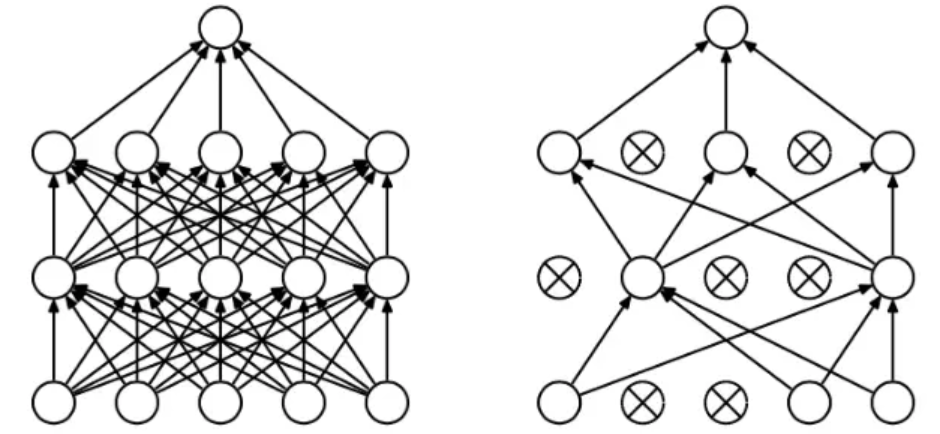 摘自https://www.jianshu.com/p/b5e93fa01385
摘自https://www.jianshu.com/p/b5e93fa01385
recurrent_drop:同理,因为这里有两个输入所以就有两个dropout。 return_sequences: 是返回输出序列中的最后一个输出(False)还是完整序列(True)。 return_state: 除输出外,是否返回最后一个状态。 go_backwards:如果为True,则向后处理输入序列,并返回相反的序列。 stateful:如果为True,则将批次中索引为 i 的每个样本的最后状态用作下一个批次中索引为 i 的样本的初始状态。 unroll:如果为True,则将展开网络,否则将使用符号循环。 展开可以加快RNN的速度,尽管它往往会占用更多的内存。 展开仅适用于短序列。
SimpleRNN‘s example
1 | from keras.layers import SimpleRNN |
直接运行结果
1 | _________________________________________________________________ |
about return_sequences
1 | layer = SimpleRNN(3,use_bias=False,return_sequences=True) |
1 | layer = SimpleRNN(3,use_bias=False,return_sequences=False) |
about return_state
1 | return_state=False: |
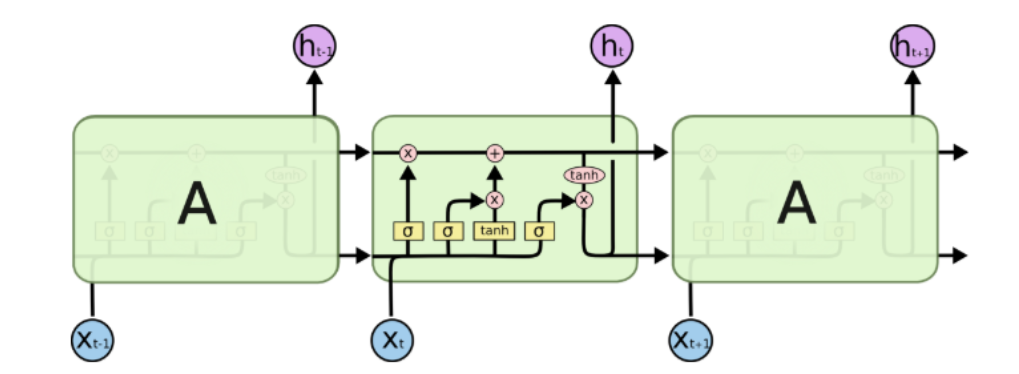
循环神经网络(二) | GRU和LSTM
开篇
图示对比
RNN
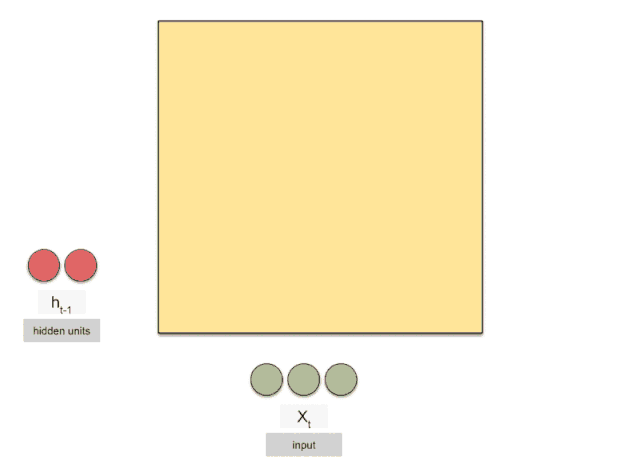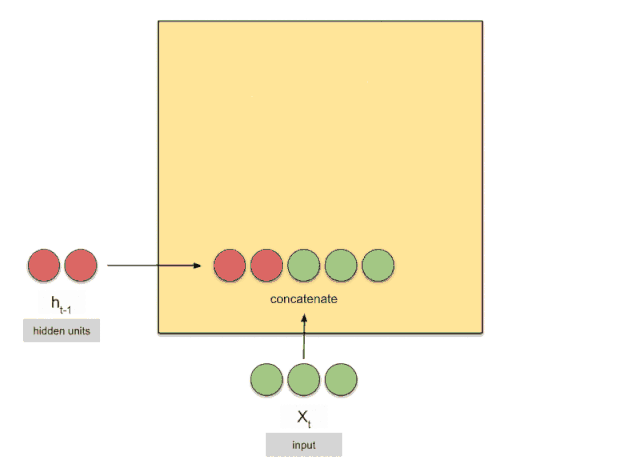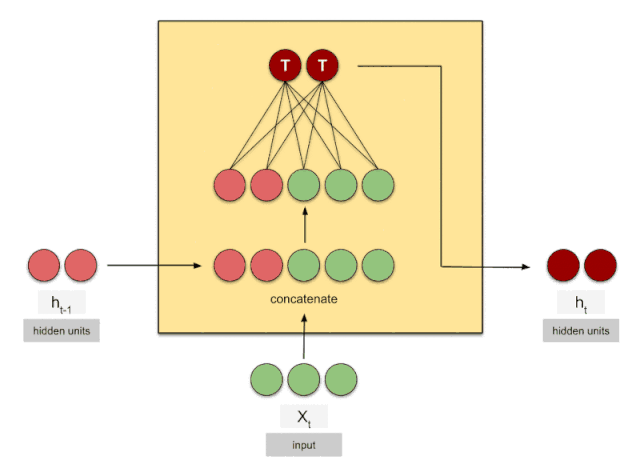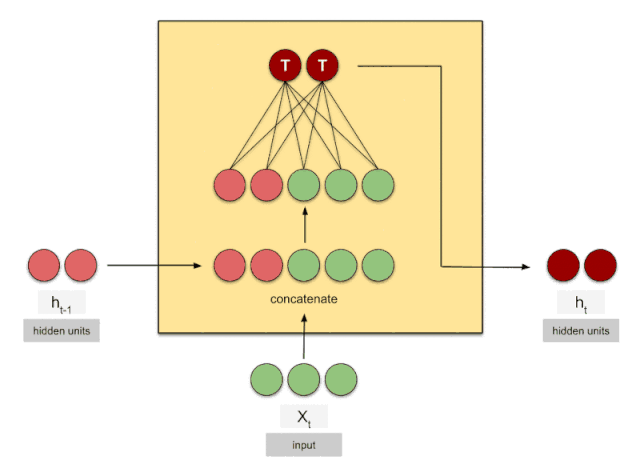
LSTM
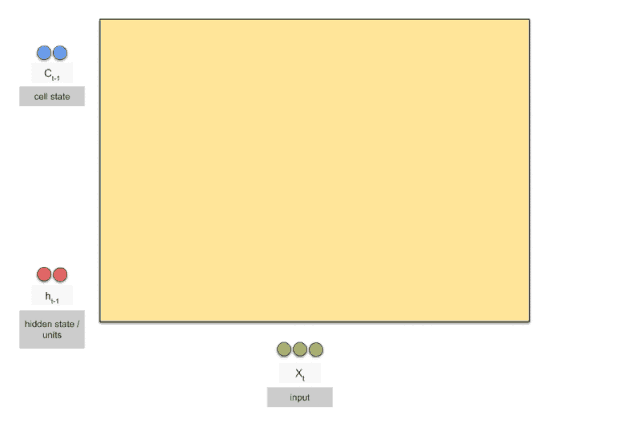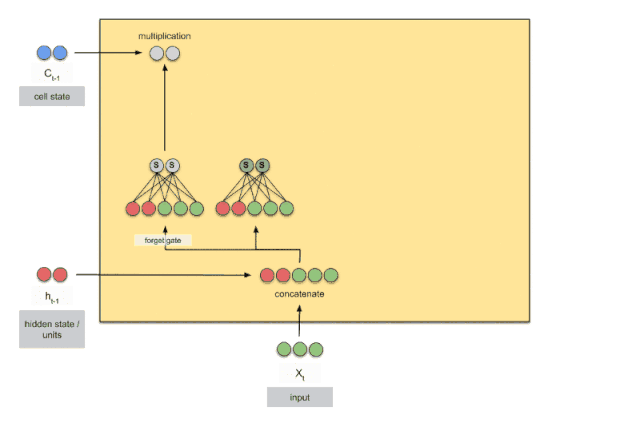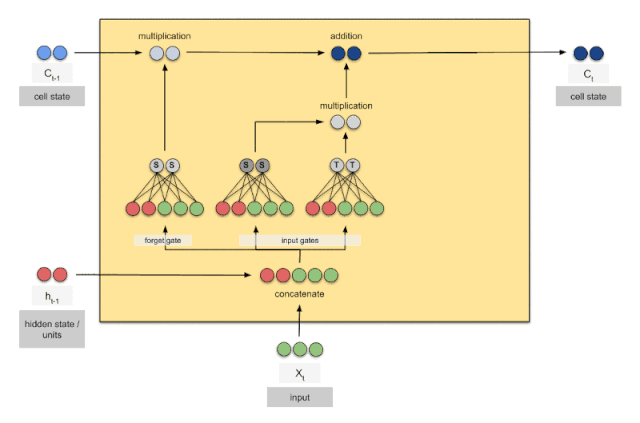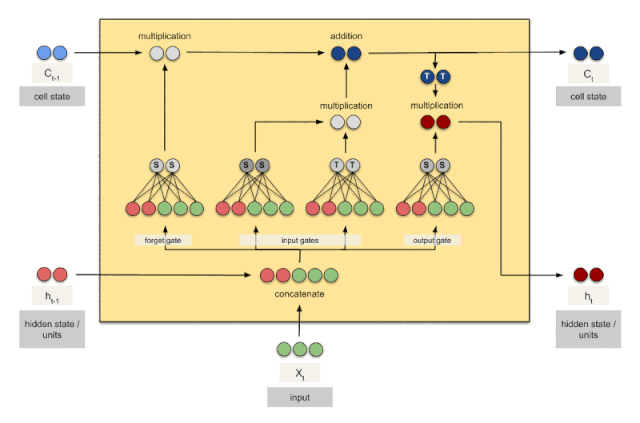
GRU
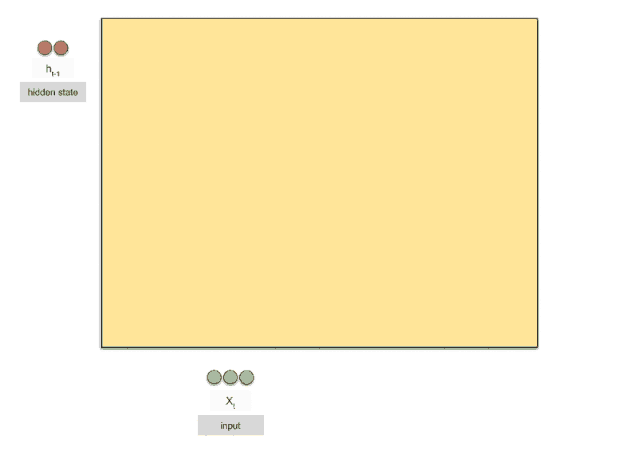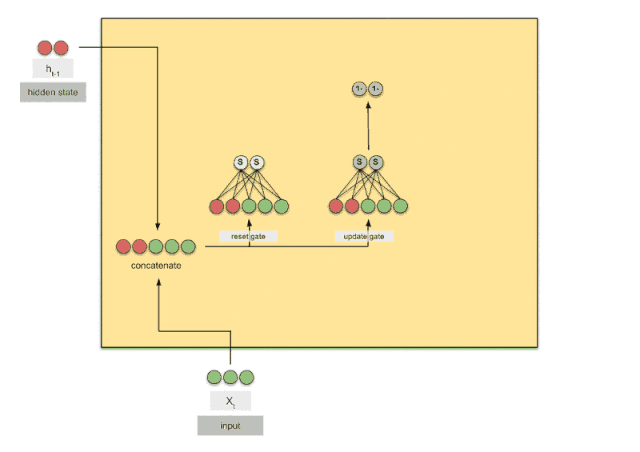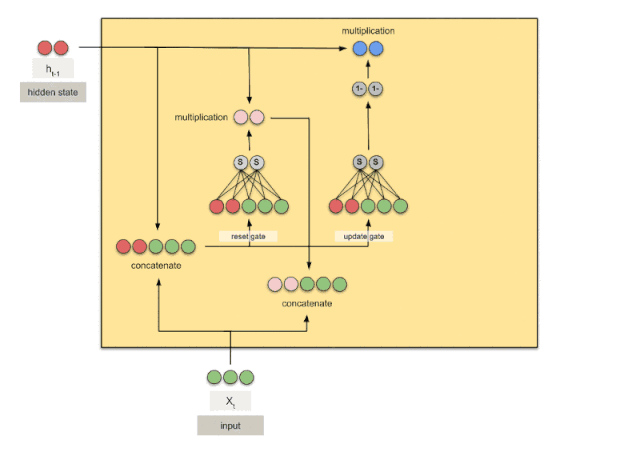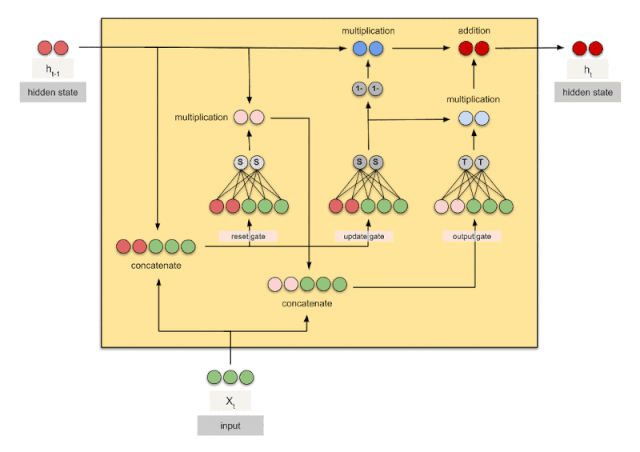
优化的点
在RNN中,随着时间线的延长,距离目前时间比较远的数据所包含的信息会被衰减殆尽,举个例子
“I grew up in France… I speak fluent ?.” 我们现在想判断出 ?处应该是什么,我们直观地判断结果应该是Franch,判断的依据是前面有个France,可以认为France是\(x_4\)的数据,我们要推断的是\(x_t(t \geq 8)\)的数据。对RNN而言,这两个单词离得太远了,因此解决不了。
LSTM
本质上增加了存储的信息量,可以认为\(C_t\)中保留了从开始到现在所有需要的信息。这是长期知识,然后通过与RNN中已经提供的短期知识结合,共同判断结果。细致的讲解可以参看下面的博客。
https://www.jianshu.com/p/95d5c461924c
GRU
效果跟LSTM差不多,但是节省了更多的计算资源,因为没有细胞状态了。细致原理参看下面的文章。
https://zhuanlan.zhihu.com/p/32481747
keras实现
LSTM
1 | keras.layers.LSTM(units, activation='tanh', recurrent_activation='sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, implementation=2, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False) |
具体参数的含义在中基本ref都已经介绍过了,这里新增的两个activation通过默认值可以直接与lstm的结构对应上。
GRU
1 | keras.layers.GRU(units, activation='tanh', recurrent_activation='sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, implementation=2, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False, reset_after=False) |
参考
https://baijiahao.baidu.com/s?id=1639105801622260740&wfr=spider&for=pc
图片摘自https://www.jianshu.com/p/95d5c461924c
循环神经网络(三) | LSTM
什么作用
如果用一句话总结LSTM的作用,它可以用来处理时序数据;如果用一句话总结卷积的作用,它用来处理空间数据。那如果是音频呢,图片随着时间变化,那我们就会想基于卷积和LSTM的结合来解决这个问题。
什么样子
/cotent.assets/1587168767734.png) 在处理图像时,我们通常先将数据处理成一维向量,这个过程一般通过卷积来完成,在得到了图像的一维卷积之后,我们就可以将数据接在LSTM上了。因此LSTM的结构并没有本质改变,一个表示卷积LSTM的cell如图所示。
在处理图像时,我们通常先将数据处理成一维向量,这个过程一般通过卷积来完成,在得到了图像的一维卷积之后,我们就可以将数据接在LSTM上了。因此LSTM的结构并没有本质改变,一个表示卷积LSTM的cell如图所示。
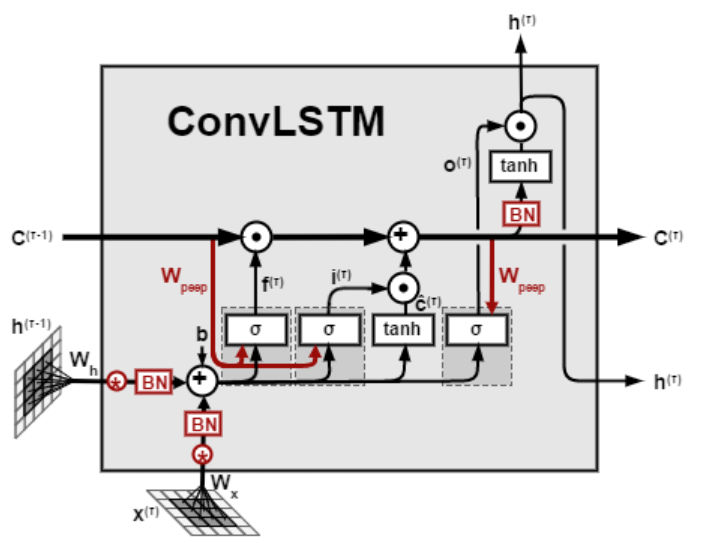
keras实现
1 | keras.layers.ConvLSTM2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, return_sequences=False, go_backwards=False, stateful=False, dropout=0.0, recurrent_dropout=0.0) |
layer的参数还是卷积和LSTM的参数,并不难理解。
无监督学习的应用
在moving-mnist数据集上对序列信息进行预测。
数据集地址:http://www.cs.toronto.edu/~nitish/unsupervised_video/mnist_test_seq.npy
代码地址:http://www.cs.toronto.edu/~nitish/unsupervised_video/unsup_video_lstm.tar.gz
在论文 Unsupervised Learning of Video Representations using LSTMs 中对该任务进行了详细描述。
http://www.cs.toronto.edu/~nitish/unsup_video.pdf
循环神经网络(四) | 自制循环神经网络
写在开篇
什么是Cell呀?Cell可以理解为循环神经网络的一个单元,如图所示。如果一个网络被定义为 \[ \begin{equation} h_t = \mathcal{F}(h_{t - 1},X_t) \end{equation} \] 那么\(\mathcal{F}\)就是这篇文章要讲的Cell。
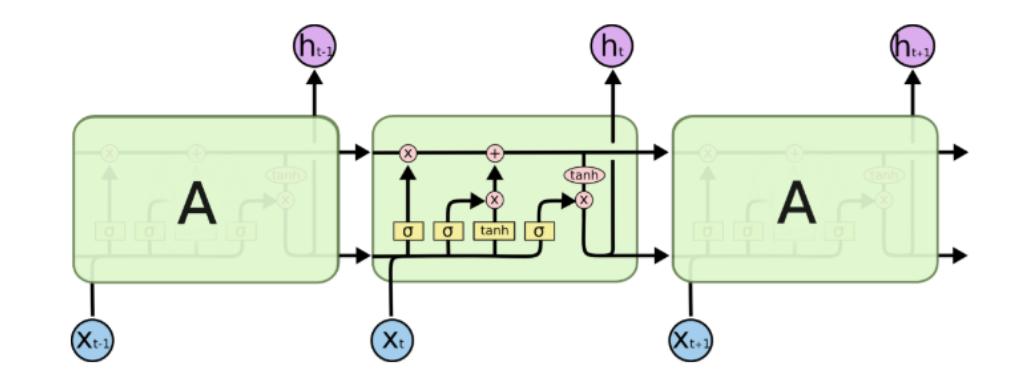
换言之,Keras中提供了自定义循环神经网络中的每个计算单元的接口,接下来就结合官方文档给出的一个例子进行分析。
API
自定义下面的代码已经调试过,可直接运行
1 | from keras.layers import * |
其中MinimalRNNCell继承Layer类,是一个实现的Cell,按照官网的说法,call函数是必须实现的,也就是\(\mathcal{F}\) 真正做的事情,其中输入输出分别是 (input_at_t, states_at_t) 和 (output_at_t, states_at_t_plus_1)。state_size和output_size也必须指明,在实现时units通常代表output_size。build函数在这里不是必须的,它本来是Layer类的函数,在这里override了。
封装Cell类
除了可以自定义之外,keras也提供了已经封装好了的Cell类,比如:ConvLSTM2DCell,SimpleRNNCell,GRUCell,LSTMCell。这些类的参数就不再显示在这里了,因为他们跟自己对应的Layer的参数一摸一样,举一个例子,如下所示。
1 | # 先是卷积LSTM的层的声明 |
既然参数一样,为什么还要制作两个接口呢?其实在使用cell创建RNN层时,可以一次传入多个cell,这样的Layer叫stacked RNN,比如:
1 | cells = [MinimalRNNCell(32), MinimalRNNCell(64)] |
而通常封装的API都是一个Cell的。因此,分别给出来有一定的意义。
最后
在循环神经网络部分,总共有三种神经网络,分别是RNN,GRU,LSTM,这些都用来处理时间序列的数据。除此之外还有在gpu下使用的版本,在keras中的名字就是CuDNN。
循环神经网络(五) | 双向循环神经网络
写在开篇
在keras的循环层\(GRU\) 、\(LSTM\)等中的keras声明中,有一个叫做\(go\_backwards\)的参数。参数的取值为\(true\)或者\(false\)。如果取值为\(true\),输入的序列数据就会被反向处理,并且默认是\(false\),也就是正向处理数据。举个例子,比如\(RNN\)的输入是\(a,b,c,d,e\),如果\(go\_backwards=true\),输入就是\(e,d,c,b,a\)。\(go\_backwards\)参数的设置具有一定的意义。
\(go\_backwards\) 的意义所在
循环神经网络本质上处理的是时序信息,或者是分先后顺序的信息。在文本的处理中经常用到,在此不做深究,我们只认为\(RNN\)的处理结果中包含了,时序信息。而且包含的时序信息越多,处理的效果就越好。而正序处理和倒序处理包含了不同的时序信息。这是\(go\_backwards\)参数的意义所在,也是双向循环层的意义所在。
Bidirectional
整体效果
在一次处理中,正向处理一遍,反向处理一遍,时间代价不变,空间代价加倍,获取更多序列信息。
keras实现
1 | tf.keras.layers.Bidirectional( |
\(keras\)中的\(Bidirectional\)其实不是一个单独的layer,而是一个wrapper。先看一个例子。
1 | model = Sequential() |
在声明中,我们需要实例化两个循环神经网络层,这个循环层可以是\(RNN,LSTM,GRU\)等,然后将这两个实例化层作为参数传给tf.keras.layers.Bidirectional即可。
总结
比较核心的layer都已经讲完了,接下来会分享一些同样重要的点,比如metrics、callbacks等,他们对于准确率的提升,训练过程的控制等都有重要意义。
标准化层
各位读者大家好,今天我们要一起来学习Keras的标准化层。首先,我会通过图解为大家讲解一下标准化层都做了什么,之后再为大家展示Keras中的标准化层函数。那接下来就让我们开始今天的学习吧!
Keras中的标准化层实际上就是批量标准化。它与普通的数据标准化类似,将分散的数据进行统一,有利于网络对于数据之中规律的学习。
我们先来看看数据标准化的必要性。
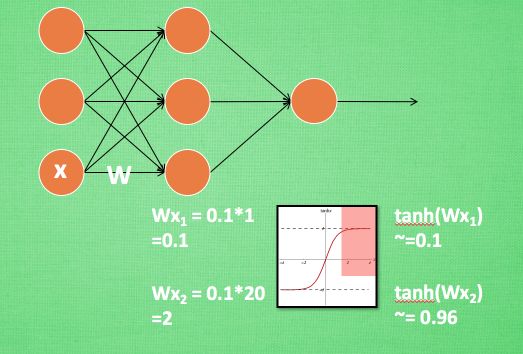
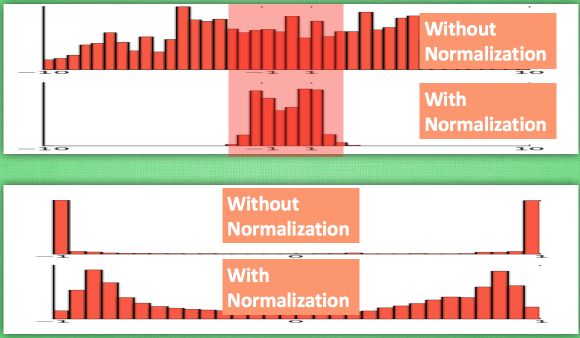
从图中可以看出,在神经网络中,当我们使用像tanh这样的激活函数之后,如果Wx的激活值在激励函数的饱和阶段时(如图中的红色部分所示),那么一个极大的值和一个较小的值经过激活函数处理之后的差别不大,即神经网络对较大的x特征范围不再敏感。这是很不好的事情,就像一个人已经无法感受到轻轻的拍打和重重一拳的区别了,这意味着感受能力大大降低。所以批标准化应运而生,来解决这件可怕的事情。它会对输入进行处理,使得数据进入激励函数的敏感部分,加强网络的学习能力。
一般批标准化层添加在每一个全连接和激励函数之间,对全连接层的计算结果经过标准化处理再经过激励函数处理。
计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 标准化, 下者进行了 标准化, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程。
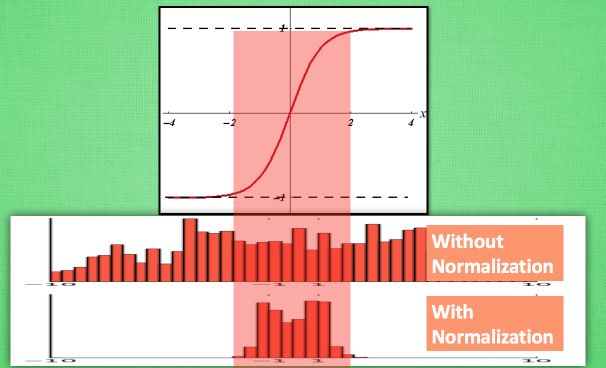
由下图可以看出,没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值。Keras的标准化层不仅会标准化数据,还会反标准化数据。
BatchNormalization
1 | keras.layers.BatchNormalization( |
作用:批量标准化,在每一个批次的数据中标准化前一层的激活项, 即应用一个维持激活项平均值接近 0,标准差接近 1 的转换。
输入尺寸:可以是任意的。如果将这一层作为模型的第一层,则需要指定 input_shape参数(整数元组,不包含样本数量的维度)。
输出尺寸:与输入相同
相信大家经过今天的学习,能够对标准化层的功能有一个清晰的认知,标准化层是非常重要的网络层,它可以用于改善人工神经网络的性能和稳定性,使机器学习更容易学习到数据之中的规律。 所以希望各位能亲手实践以对它有更好地认识,大家一起加油!
池化层
各位读者大家好,上周我们详细讲解了Keras的核心网络层,相信大家已经对核心网络层的作用以及使用方法有了一个清晰的认识。这周我们将要开展池化层和卷积层的讲解了,这篇文章就是对池化层的讲解。
首先我们要统一说一下池化层的作用。池化层放在连续的卷积层中间,用于压缩数据和参数的量,防止过拟合。其具体操作与卷积层的操作基本相同,只不过池化层的卷积核只取对应位置的最大值、平均值等(最大池化、平均池化),且不经过反向传播的修改。总结一下,作用有两个:①invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度);②保留主要的特征同时减少参数(降维,效果类似PCA)和计算量,防止过拟合,提高模型泛化能力。
池化层操作又分为平均池化和最大池化。根据相关理论,特征提取的误差主要来自两个方面:①邻域大小受限造成的估计值方差增大;②卷积层参数误差造成估计均值的偏移。一般来说,平均池化能减小第一种误差,更多地保留图像的背景信息,最大池化能减小第二种误差,更多地保留纹理信息。
池化层的操作方式我们可以通过以下的图片来清晰地了解。

最大池化图示
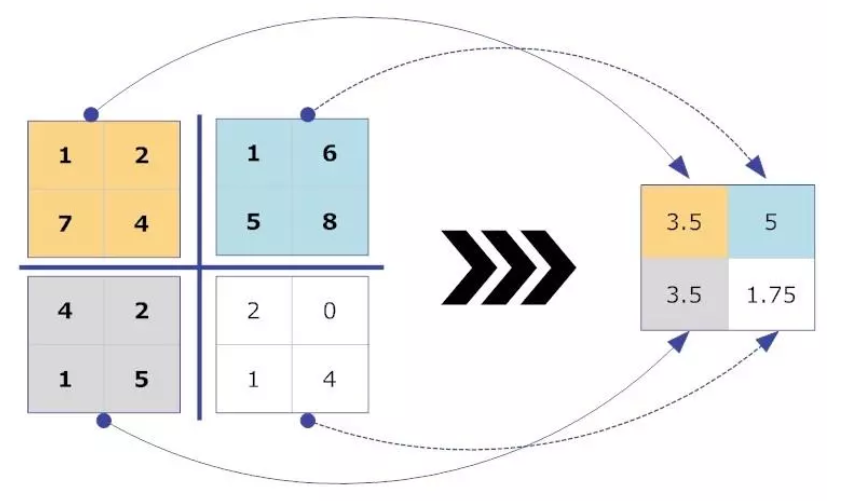
平均池化图示
全局池化操作即是对指定的张量的全局数据进行最大池化或者平均池化操作。池化层中的1D是对时序数据进行池化操作,2D是对空间数据进行池化操作,3D是对空间或时空间数据进行池化操作。
MaxPooling1D层
1 | keras.layers.MaxPooling1D( |
输入尺寸:
如果 data_format='channels_last',输入为 3D 张量,尺寸为:(batch_size, steps, features)
如果data_format='channels_first',输入为 3D 张量,尺寸为:(batch_size, features, steps)
输出尺寸:
如果 data_format='channels_last',输出为 3D 张量,尺寸为:(batch_size, downsampled_steps, features)
如果data_format='channels_first',输出为 3D 张量,尺寸为:(batch_size, features, downsampled_steps)
MaxPooling2D层
1 | keras.layers.MaxPooling2D( |
输入尺寸:
如果 data_format='channels_last: 尺寸是 (batch_size, rows, cols, channels)的 4D 张量
如果 data_format='channels_first': 尺寸是 (batch_size, channels, rows, cols)的 4D 张量
输出尺寸:
如果 data_format='channels_last: 尺寸是 (batch_size, pooled_rows, pooled_cols, channels)的 4D 张量
如果 data_format='channels_first': 尺寸是 (batch_size, channels, pooled_rows, pooled_cols)的 4D 张量
MaxPooling3D层
1 | keras.layers.MaxPooling3D( |
输入大小:
如果data_format='channels_last': 尺寸是 (batch_size, spatial_dim1, spatial_dim2, spatial_dim3, channels)的 5D 张量
如果data_format='channels_first': 尺寸是 (batch_size, channels, spatial_dim1, spatial_dim2, spatial_dim3)的 5D 张量
输出大小:
如果data_format='channels_last': 尺寸是 (batch_size, pooled_dim1, pooled_dim2, pooled_dim3, channels)的 5D 张量
如果data_format='channels_first': 尺寸是 (batch_size, channels, pooled_dim1, pooled_dim2, pooled_dim3)的 5D 张量
AveragePooling1D层
1 | keras.layers.AveragePooling1D( |
输入尺寸:
如果 data_format='channels_last',输入为 3D 张量,尺寸为:(batch_size, steps, features)
如果data_format='channels_first',输入为 3D 张量,尺寸为:(batch_size, features, steps)
输出尺寸:
如果 data_format='channels_last',输出为 3D 张量,尺寸为:(batch_size, downsampled_steps, features)
如果data_format='channels_first',输出为 3D 张量,尺寸为:(batch_size, features, downsampled_steps)
AveragePooling2D层
1 | keras.layers.AveragePooling2D( |
输入尺寸:如果 data_format='channels_last: 尺寸是 (batch_size, rows, cols, channels)的 4D 张量
如果 data_format='channels_first': 尺寸是 (batch_size, channels, rows, cols)的 4D 张量
输出尺寸:如果 data_format='channels_last: 尺寸是 (batch_size, pooled_rows, pooled_cols, channels)的 4D 张量
如果 data_format='channels_first': 尺寸是 (batch_size, channels, pooled_rows, pooled_cols)的 4D 张量
AveragePooling3D层
1 | keras.layers.AveragePooling3D( |
输入大小:如果data_format='channels_last': 尺寸是 (batch_size, spatial_dim1, spatial_dim2, spatial_dim3, channels)的 5D 张量
如果data_format='channels_first': 尺寸是 (batch_size, channels, spatial_dim1, spatial_dim2, spatial_dim3)的 5D 张量
输出大小:如果data_format='channels_last': 尺寸是 (batch_size, pooled_dim1, pooled_dim2, pooled_dim3, channels)的 5D 张量
如果data_format='channels_first': 尺寸是 (batch_size, channels, pooled_dim1, pooled_dim2, pooled_dim3)的 5D 张量
GlobalMaxPooling1D层
1 | keras.layers.GlobalMaxPooling1D( |
输入尺寸:如果 data_format='channels_last',输入为 3D 张量,尺寸为:(batch_size, steps, features)
如果data_format='channels_first',输入为 3D 张量,尺寸为:(batch_size, features, steps)
输出尺寸:尺寸是 (batch_size, features) 的 2D 张量。
GlobalMaxPooling2D层
1 | keras.layers.GlobalMaxPooling3D( |
输入尺寸:如果 data_format='channels_last: 尺寸是 (batch_size, rows, cols, channels)的 4D 张量
如果 data_format='channels_first': 尺寸是 (batch_size, channels, rows, cols)的 4D 张量
输出尺寸:尺寸是 (batch_size, channels) 的 2D 张量。
GlobalMaxPooling3D层
1 | keras.layers.GlobalMaxPooling3D( |
输入大小:如果data_format='channels_last': 尺寸是 (batch_size, spatial_dim1, spatial_dim2, spatial_dim3, channels)的 5D 张量
如果data_format='channels_first': 尺寸是 (batch_size, channels, spatial_dim1, spatial_dim2, spatial_dim3)的 5D 张量
输出尺寸:尺寸是 (batch_size, channels) 的 2D 张量。
GlobalAveragePooling1D层
1 | keras.layers.GlobalAveragePooling1D( |
输入尺寸:如果 data_format='channels_last',输入为 3D 张量,尺寸为:(batch_size, steps, features)
如果data_format='channels_first',输入为 3D 张量,尺寸为:(batch_size, features, steps)
输出尺寸:尺寸是 (batch_size, features) 的 2D 张量。
GlobalAveragePooling2D层
1 | keras.layers.GlobalAveragePooling2D( |
输入尺寸:如果 data_format='channels_last: 尺寸是 (batch_size, rows, cols, channels)的 4D 张量
如果 data_format='channels_first': 尺寸是 (batch_size, channels, rows, cols)的 4D 张量
输出尺寸:尺寸是 (batch_size, channels) 的 2D 张量。
GlobalAveragePooling3D层
1 | keras.layers.GlobalAveragePooling3D( |
输入大小:如果data_format='channels_last': 尺寸是 (batch_size, spatial_dim1, spatial_dim2, spatial_dim3, channels)的 5D 张量
如果data_format='channels_first': 尺寸是 (batch_size, channels, spatial_dim1, spatial_dim2, spatial_dim3)的 5D 张量
输出尺寸:尺寸是 (batch_size, channels) 的 2D 张量。
相信大家经过今天的学习,能够获得对池化层的作用以及使用方式的认识,池化层是卷积神经网络的重要组成部分,希望大家在课下可以多多找实例进行再进一步的了解,让我们一起期待明天的卷积层教程吧!
噪声层
各位读者大家好,今天我们要一起来学习Keras的噪声层。在神经网络的研究和应用中,经常会出现噪声层的身影,许多正则化的方法通过向训练数据添加噪声来防止过拟合,提高神经网络的鲁棒性。下面让我们来一起看看Keras噪声层的类型。
GaussianNoise层
1 | keras.layers.GaussianNoise(stddev #float,噪声分布的标准差 |
作用:
高斯分布即为正态分布,该网络层添加均值为0,标准差为stddev的高斯噪声。
这对缓解过拟合很有用 (你可以将其视为随机数据增强的一种形式)。 高斯噪声(GS)是对真实输入的腐蚀过程的自然选择。
由于它是一个正则化层,因此它只在训练时才被激活。
输入尺寸:
可以是任意的。 如果将该层作为模型的第一层,则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
GaussianDropout层
1 | keras.layers.GaussianDropout(rate #float,丢弃概率(与 Dropout 相同)。 这个乘性噪声的标准差为 sqrt(rate/(1 - rate)) |
功能:添加均值为1,标准差为sqrt{frac{rate}{1-rate} }的高斯噪声。
由于它是一个正则化层,因此它只在训练时才被激活。
输入尺寸:
可以是任意的。 如果将该层作为模型的第一层,则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:与输入相同。
AlphaDropout层
1 | keras.layers.AlphaDropout(rate, #float,丢弃概率(与 Dropout 相同)。 这个乘性噪声的标准差为 sqrt(rate/(1 - rate)) |
功能:将 Alpha Dropout 应用到输入。
Alpha Dropout 是一种 Dropout, 删除一定比例的输入,使得输出的均值和方差与输入的均值和方差很接近,保持数据的自规范性, 以确保即使在 dropout 后也能实现自我归一化。 通过随机将激活设置为负饱和值, Alpha Dropout 非常适合按比例缩放的指数线性单元(SELU)。噪声的标准差为sqrt{frac{rate}{1-rate} }。
输入大小:可以是任意的。 如果将该层作为模型的第一层,则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出大小:与输入相同。
相信大家经过今天的学习,能够对噪声层层的类型和功能有一个清晰的认知,融合层是比较重要的网络层,虽然简单但很重要,它在解决神经网络过拟合方面有较为重要的作用,所以希望各位能亲手实践以对它有更好地认识,大家一起加油!
高级激活层
各位读者大家好,今天我们要一起来学习Keras的高级激活层,它实际上就是激活函数的Model类API用法,与激活函数效果相同。激活层是非常重要的网络层,它将非线性变化引入了网络中,使网络可以任意逼进任何非线性函数中,给了神经网络更加强大的功能。没有激活函数的每层都相当于矩阵相乘,就算你叠加了若干层之后,无非还是个矩阵相乘罢了。可以说神经网络的成功与激活层密不可分。那接下来就让我们开始今天的学习吧!
LeakyReLU层
1 | keras.layers.LeakyReLU(alpha=0.3 #alpha: float >= 0。负斜率系数 |
作用:
LeakyRelU是修正线性单元( Rectified Linear Unit, ReLU)的特殊版本,当不激活时, LeakyReLU仍然会有非零输出值,从而获得一个小梯度,避免ReLU可能出现的神经元“死亡”现象。
当神经元未激活时,它仍允许赋予一个很小的梯度: f(x)=max(0,x)+negative_slope×min(0,x), 其中,negative_slope是一个小的非零数。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输入尺寸:
可以是任意的。如果将该层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同
PReLU层
1 | keras.layers.PReLU(alpha_initializer='zeros', #权重的初始化函数 |
功能:
该层为参数化的ReLU( Parametric ReLU)。
形如 f(x) = alpha * x for x < 0, f(x) = x for x >= 0, 其中 alpha 是一个可学习的数组,尺寸与 x 相同。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
ELU层
1 | keras.layers.ELU(alpha=1.0 #负因子的尺度 |
功能:
ELU层是指数线性单元( Exponential Linera Unit)。
形如 f(x) = alpha * (exp(x) - 1.) for x < 0, f(x) = x for x >= 0
输入大小:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出大小:
与输入相同。
ThresholdedReLU层
1 | keras.layers.ThresholdedReLU(theta=1.0 #theta: float >= 0。激活的阈值位) |
功能:
该层是带有门限的ReLU
形式: f(x) = x for x > theta, 否则f(x) = 0。
输入:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出:
与输入相同。
Softmax层
1 | keras.layers.Softmax(axis=-1 #整数,应用 softmax 标准化的轴 |
功能:
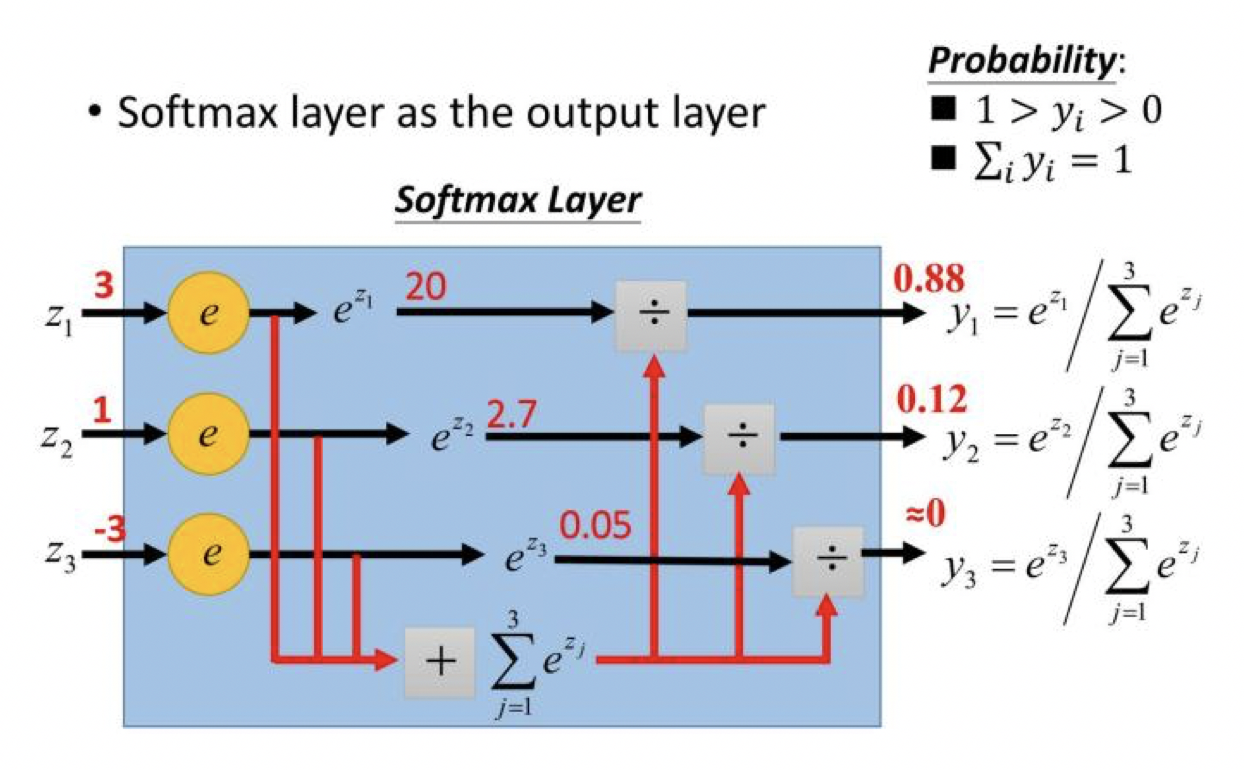
softmax把一个k维的real value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….)其中bi是一个0-1的常数,然后可以根据bi的大小来进行多分类的任务。公式如下:
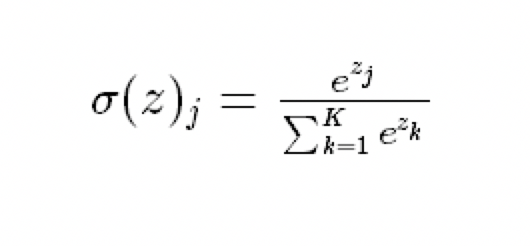
应用实例:
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
ReLU层
1 | keras.layers.ReLU(max_value=None, #浮点数,最大的输出值 |
功能:
Relu是最常用的默认激活函数,若不确定用哪个激活函数,就使用Relu或者LeakyRelu
Relu激活函数(The Rectified Linear Unit),用于隐层神经元输出。公式如下
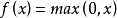
函数图像如下:
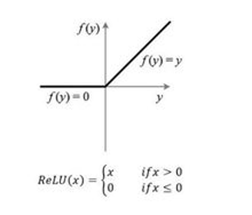
它与其他激活函数最大的不同在于它是线性的,因而不存在梯度爆炸的问题,在多层网络结构下梯度会线性传递。
在深度学习中Relu是用的最广泛的一种激活函数。
使用默认值时,它返回逐个元素的 max(x,0)。
否则:
- 如果
x >= max_value,返回f(x) = max_value, - 如果
threshold <= x < max_value,返回f(x) = x, - 否则,返回
f(x) = negative_slope * (x - threshold)。
输入尺寸:
可以是任意的。如果将这一层作为模型的第一层, 则需要指定 input_shape 参数 (整数元组,不包含样本数量的维度)。
输出尺寸:
与输入相同。
相信大家经过今天的学习,能够对高级激活层的类型和功能有一个清晰的认知,激活层是非常重要的网络层,对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用,它们给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。 所以希望各位能亲手实践以对它有更好地认识,大家一起加油!
局部连接层
上周我们刚刚结束了Keras卷积层的学习,卷积层事实上就是一种特殊的局部连接层。那么这周我们就来趁热打铁,来学习一下Keras的局部连接层。
局部连接层区别于全连接层,局部连接层也称为局部感知或稀疏连接,可以用来提取局部特征并且起到减少参数的作用。
局部连接示意图
LocallyConnected1D层
1 | keras.layers.LocallyConnected1D( |
作用:
对于时序数据进行局部连接。LocallyConnected1D层与Conv1D层的工作方式相同,除了权值不共享外, 也就是说,在输入的每个不同部分应用不同的一组过滤器。
输入尺寸:
3D 张量,尺寸为: (batch_size, steps, input_dim)。
输出尺寸:
3D 张量 ,尺寸为:(batch_size, new_steps, filters),steps值可能因填充或步长而改变。
例子:
1 | # 将长度为3的非共享权重1D卷积应用于 |
LocallyConnected2D层
1 | keras.layers.LocallyConnected2D( |
作用:
对于空间数据进行局部连接。LocallyConnected2D层与Conv2D层的工作方式相同,除了权值不共享外, 也就是说,在输入的每个不同部分应用不同的一组过滤器。
输入尺寸:
4D 张量,尺寸为: (samples, channels, rows, cols),如果 data_format='channels_first'; 或者 4D 张量,尺寸为: (samples, rows, cols, channels),如果 data_format='channels_last'。
输出尺寸:
4D 张量,尺寸为: (samples, filters, new_rows, new_cols),如果 data_format='channels_first'; 或者 4D 张量,尺寸为: (samples, new_rows, new_cols, filters),如果 data_format='channels_last'。 rows 和 cols 的值可能因填充而改变。
例子:
1 | # 在 32x32 图像上应用 3x3 非共享权值和64个输出过滤器的卷积 |
相信大家经过今天的学习,能够获得对局部连接层的作用以及使用方式的认识,局部连接层是减少网络参数的重要途径,希望大家在课下可以多多找实例进行再进一步的了解,让我们一起期待明天的RNN层教程吧!
融合层
各位读者大家好,上周我们已经详细讲解了Keras的卷积层和池化层,相信大家经过学习已经对两者有了一个清晰的认识,也能更好地把它们运用到图像处理中。池化层和卷积层是非常重要的网络层类型,大家在学习之后也需要动手实践去更好地理解它们。鉴于上周学习了比较难的网络层,那么今天我们就来放松一下,学习Keras中比较简单的融合层。让我们开始今天的学习吧
Add层
1 | keras.layers.Add() |
作用:
计算输入张量列表的和。
输入尺寸:
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
输出尺寸:
一个张量,与输入张量列表的张量尺寸一致。
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
Subtract层
1 | keras.layers.Subtract() |
功能:
计算两个输入张量的差。
输入尺寸:
它接受一个长度为 2 的张量列表, 两个张量必须有相同的尺寸,然后返回一个值为 (inputs[0] - inputs[1]) 的张量, 输出张量和输入张量尺寸相同。
输出尺寸:
一个张量,与输入张量列表的张量尺寸一致。
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
Multiply层
1 | keras.layers.Multiply() |
功能:
计算输入张量列表的(逐元素间的)乘积。
输入大小:
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
输出大小:
一个张量,与输入张量列表的张量尺寸一致。
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
Average层
1 | keras.layers.Average() |
功能:
计算输入张量列表的平均值。
输入:
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
输出:
一个张量,与输入张量列表的张量尺寸一致。
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
Maximum层
1 | keras.layers.Maximum() |
功能:
计算输入张量列表的(逐元素间的)最大值。
输入尺寸:
它接受一个张量的列表, 所有的张量必须有相同的输入尺寸, 然后返回一个张量(和输入张量尺寸相同)。
输出尺寸:
一个张量,与输入张量列表的张量尺寸一致。
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
Concatenate层
1 | keras.layers.Concatenate( |
功能:
连接一个输入张量的列表。
输入尺寸:
它接受一个张量的列表, 除了连接轴之外,其他的尺寸都必须相同, 然后返回一个由所有输入张量连接起来的输出张量。
输出尺寸:
列表中所有张量根据连接轴连接之后形成的张量大小
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
Dot层
1 | keras.layers.Dot( |
功能:
计算两个张量之间样本的点积。
输入尺寸:
它接受一个长度为 2 的张量列表, 两个张量必须有相同的尺寸,假设两个张量分别为a和b,则返回一个值为∑(a[i] + b[i])的张量。
输出尺寸:
(batch_size,1)
例子:
1 | input1 = keras.layers.Input(shape=(16,)) |
相信大家经过今天的学习,能够对融合层的类型和功能有一个清晰的认知,融合层也是重要的网络层,虽然简单但很重要,它在构造结构复杂的Model类模型中起到了很重要的作用,所以希望各位能亲手实践以对它有更好地认识,大家一起加油!
包装层
写在开篇
各位读者大家好,今天我们要一起来学习Keras包装层中的两个工具:TimeDistributed 和Bidirectional。虽然并不算十分常见,但自有其神奇之处。
类型说明
TimeDistributed
TimeDistributed这个层还是比较难理解的。事实上通过这个层,可以实现从二维像三维的过渡,甚至通过这个层的包装,可以实现图像分类视频分类的转化。
1 | keras.layers.TimeDistributed(layer) |
这个封装器将一个层应用于输入的每个时间片。
输入至少为 3D,且第一个维度应该是时间所表示的维度。
考虑 32 个样本的一个 batch, 其中每个样本是 10 个 16 维向量的序列。那么这个 batch 的输入尺寸为 (32, 10, 16), 而 input_shape 不包含样本数量的维度,为 (10, 16)。使用 TimeDistributed 来将 Dense 层独立地应用到 这 10 个时间步的每一个:
可以这么理解,输入数据是一个特征方程,X1+X2+...+X10=Y,从矩阵的角度看,拿出未知数Y,就是10个向量,每个向量有16个维度,这16个维度是评价Y的16个特征方向。TimeDistributed层的作用就是把Dense层应用到这10个具体的向量上,对每一个向量进行了一个Dense操作,假设是下面这段代码:
1 | # 作为模型第一层 |
输出的尺寸为 (32, 10, 8)。输出还是10个向量,但是输出的维度由16变成了8。
在后续的层中,将不再需要指定 input_shape:
1 | model.add(TimeDistributed(Dense(32))) |
输出的尺寸为 (32, 10, 32)。
TimeDistributed 可以应用于任意层,不仅仅是 Dense, 例如运用于 Conv2D 层:
1 | model = Sequential() |
Bidirectional
1 | keras.layers.Bidirectional(layer, merge_mode='concat', weights=None) |
RNN 的双向封装器,对序列进行前向和后向计算。
参数
- layer:
Recurrent实例。 - merge_mode: 前向和后向 RNN 的输出的结合模式。为 {'sum', 'mul', 'concat', 'ave', None} 其中之一。如果是 None,输出不会被结合,而是作为一个列表被返回。
异常
- ValueError: 如果参数
merge_mode非法。
例
1 | model = Sequential() |
Bidirectional一个常用的例子是双向LSTM,下面的例程展示了如何在IMDB情绪分类任务中,训练一个Bidirectional LSTM模型。
1 | from __future__ import print_function |
写在文末
相信大家经过今天的学习,能够对包装层的两个工具有一定的认识。文末还为有兴趣实践的读者附上了Bidirectional的使用例,感兴趣的读者不妨动手一试。
嵌入层
畅游人工智能之海 带你学习Keras的嵌入层
写在开篇
mbedding 实际上是一种映射,将单词从原先的表示映射到新的多维空间中,在这个多维空间中,词向量之间的距离表征了单词之间的语义相关性。例如,cat 和 kitten语义相近,而cow和cat语义相差就比较远,因此一个好的嵌入模型应该能正确的将cat 和kitten放的比较近,同时cat和cow的距离相对较远。
类型说明
Embedding
嵌入层 其作用是将正整数(索引值)转换为固定尺寸的稠密向量。例如:[[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]],只能用作模型中的第一层。
1 | keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None) |
例子
1 | model = Sequential() |
参数
- input_dim: int > 0。词汇表大小, 即,最大整数 index + 1。
- output_dim: int >= 0。词向量的维度。
- embeddings_initializer:
embeddings矩阵的初始化方法 - embeddings_regularizer:
embeddingsmatrix 的正则化方法 - embeddings_constraint:
embeddingsmatrix 的约束函数 - mask_zero: 是否把 0 看作为一个应该被遮蔽的特殊的 "padding" 值。这对于可变长的 循环神经网络层 十分有用。如果设定为
True,那么接下来的所有层都必须支持 masking,否则就会抛出异常。如果 mask_zero 为True,作为结果,索引 0 就不能被用于词汇表中 (input_dim 应该与 vocabulary + 1 大小相同)。
input_length: 输入序列的长度,当它是固定的时。如果你需要连接 Flatten 和 Dense 层,则这个参数是必须的 (没有它,dense 层的输出尺寸就无法计算)。
输入尺寸
尺寸为 (batch_size, sequence_length) 的 2D 张量。
输出尺寸
尺寸为 (batch_size, sequence_length, output_dim) 的 3D 张量。
keras中的Embedding层有两种词嵌入的方式,如果需要语义特征,可以使用预训练的方式,通过参数指定预训练词向量矩阵,该词向量矩阵可以是基于任何语言模型,如Word2vec、Glove等。如果不需要语义特征,还有另一种方式是随机初始化,Embedding在随机初始化方式下是一个全连接层,而后面得到的词表示是全连接层的权重参数。
实验例子
利用GloVe预训练词向量对新闻文本进行分类
篇幅有限,只保留主要部分,所有代码请参考 在Keras模型中使用预训练的词向量
数据预处理:
先遍历下语料文件下的所有文件夹,获得不同类别的新闻以及对应的类别标签
Embedding layer设置:
接下来,从GloVe文件中解析出每个词和它所对应的词向量,并用字典的方式存储
1 | embeddings_index = {} |
此时,我们可以根据得到的字典生成上文所定义的词向量矩阵
1 | embedding_matrix = np.zeros((len(word_index) + 1, EMBEDDING_DIM)) |
现在将这个词向量矩阵加载到Embedding层中,注意,trainable=False使得这个编码层不可再训练。
1 | from keras.layers import Embedding |
一个Embedding层的输入应该是一系列的整数序列,比如一个2D的输入,它的shape值为(samples, indices),也就是一个samples行,indeces列的矩阵。每一次的batch训练的输入应该被padded成相同大小。所有的序列中的整数都将被对应的词向量矩阵中对应的列(也就是它的词向量)代替,比如序列[1,2]将被序列[词向量[1],词向量[2]]代替。这样,输入一个2D张量后,我们可以得到一个3D张量。
训练1D卷积
最后,可以使用一个小型的1D卷积解决这个新闻分类问题。
1 | sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32') |
在两次迭代之后,这个模型最后可以达到0.95的分类准确率(4:1分割训练和测试集合)。也可以利用正则方法(例如dropout)或在Embedding层上进行fine-tuning获得更高的准确率。
作为对比,也可以直接使用keras自带的Embedding层训练词向量而不用GloVe向量。
1 | embedding_layer = Embedding(len(word_index) + 1, |
写在文末
相信大家经过今天的学习,能够获得对embedding层有一个初步的认识,感兴趣的小伙伴可以自己动手做做实验,我们下次见!
时间序列数据预处理
前言
keras提供的数据预处理总共有三种类型,他们分别用于处理图片数据、时间序列数据、文本数据,这一次要解析的就是处理时间序列数据预处理,这些api将原始数据按照灵活的格式读入,输出指定格式的可直接输入到模型中的数据。用于处理时间序列数据的\(API\)总共有三个,他们分别是:\(timeseries\_dataset\_from\_array function\), \(pad\_sequences function\), \(TimeseriesGenerator class\)。
timeseries_dataset_from_array function
1 | tf.keras.preprocessing.timeseries_dataset_from_array( |
这个函数将原始数据转换成时间序列数据,所谓的一组时间序列数据就是,数据中的每一条数据都包含了相同时间长度的以当前时间点为结束的数据。
参数解释
data:输入数据
targets:说白了就是训练集的标签
sequence_length:生成的单个序列的长度
sequence_stride:生成的相邻的两个序列的第一个数据点的在原始数据中的位置间隔
sampling_rate:生成的单个序列的中的每个数据点的在原始数据中的位置间隔
shuffle:是否将生成的序列数据打乱顺序
seed:随机种子,只有使用shuffle时才用
start_index:开始下标,另一个参数对应的结束下标
举个例子
考虑输入数据 [0, 1, ... 99],使用如下参数调用该函数 sequence_length=10, sampling_rate=2, sequence_stride=3, shuffle=False,函数的返回值是:
1 | First sequence: [0 2 4 6 8 10 12 14 16 18] |
pad_sequences
1 | tf.keras.preprocessing.sequence.pad_sequences( |
这个函数用于将不同的数据补充成相同长度的数据,使用的是padding(补充数据)和truncation(截断)方法。第一个参数就是输入数据,其他的参数就不解释了,直接上例子。
1 | # 注意在实际使用这些程序时,一定要将 tf. 换成tensorflow. |
TimeseriesGenerator
1 | tf.keras.preprocessing.sequence.TimeseriesGenerator( |
与第一个函数作用相同,不再赘述,关于用法见下面这个例子。
1 | from keras.preprocessing.sequence import TimeseriesGenerator |
图像数据预处理(一)
上周我们结束了优化器的学习,这周我们将要展开数据预处理中关于图像数据预处理函数的学习。数据预处理的函数可以帮助我们将原始数据转换成可用于训练模型的对象,这也是训练神经网络的过程中非常重要的一步,让我们一起来看看吧。
image_dataset_from_directory函数
1 | tf.keras.preprocessing.image_dataset_from_directory( |
该函数会从目录中的图像文件生成 tf.data.Dataset 。
如果目录结构如下:
1 | main_directory/ |
然后调用image_dataset_from_directory(main_directory,labels='inferred'), 将返回tf.data.Dataset,从子目录class_a和生成批次图像class_b,以及标签0和1(0对应于class_a和1对应于class_b)。
支持的图像格式:jpeg,png,bmp,gif。动画gif被截断到第一帧。
返回值:
一个tf.data.Dataset对象。如果label_mode为None,它将生成形状为(batch_size,image_size[0],image_size[1],num_channels)的float32张量,对图像进行编码。否则,将生成一个元组 (images, labels),其images 形状为(batch_size, image_size[0], image_size[1], num_channels),有可能为int、binary和categorial。如果label_mode是int,标签是形如(batch_size,)的int32张量;如果label_mode是binary,,标签是形如(batch_size, 1)的0s和1s的float32张量;如果label_mode为categorial,标签是形如(batch_size, num_classes)的float32张量,表示类索引的单次编码。
如果color_mode为grayscale,则图像张量中有1个通道。如果color_mode是rgb,则图像张量中有3个通道。如果color_mode是rgba,则图像张量中有4个通道。
load_img函数
1 | tf.keras.preprocessing.image.load_img( |
将图像加载为PIL格式。
例子:
1 | image = tf.keras.preprocessing.image.load_img(image_path) |
返回:
PIL实例
注意:
ImportError:如果PIL不可用。
ValueError:如果不支持插值方法。
img_to_array函数
1 | tf.keras.preprocessing.image.img_to_array( |
返回值:
3D的numpy阵列
注意:
ValueError:如果无效img或data_format已通过。
ImageDataGenerator类
1 | tf.keras.preprocessing.image.ImageDataGenerator( |
使用实时数据增强生成一批张量图像数据。数据将被循环(分批)。
该类有多种API,如flow、flow_from_directory等等,明天我们将进行相关的讲解。
今天我们学习了一部分图像数据预处理的函数和类,大家可以动手尝试将它们运用到代码当中,及时巩固,谢谢大家的阅读,明天见!
图像数据预处理(二)
前言
tf.keras.preprocessing这个库用来将原始数据生成固定可用于训练的格式tf.data.Dataset。
flow method
1 | from tensorflow.keras.preprocessing import ImageDataGenerator |
这个函数用于生成batch数据,同时增加了一些辅助功能,其中shuffle、sample_weight、seed、subset在前面已经说过了,save_to_dir、save_prefix是配套使用的,用于将生成的数据保存在硬盘上。
flow_from_dataframe method
1 | ImageDataGenerator.flow_from_dataframe( |
用于处理pandas格式下的dataframe,并返回标准化的batch数据。directory实际上是目标程序运行时要读取的路径,在这个函数中相当于是输出路径。在 https://medium.com/@vijayabhaskar96/tutorial-on-keras-imagedatagenerator-with-flow-from-dataframe-8bd5776e45c1 这篇博客中提到了另一种使用该函数的方法:先在命令行中执行 pip uninstall keras-preprocessing,pip install git+https://github.com/keras-team/keras-preprocessing.git ,然后使用from keras_preprocessing.image import ImageDataGenerator调用这个类即可。
关于一个使用该函数的例子如下所示,其中数据集可以到这里获取: https://www.kaggle.com/c/cifar-10/data
1 | import pandas as pd |
flow_from_directory method
1 | ImageDataGenerator.flow_from_directory( |
从某个目录直接获取数据并生成batch数据,但是数据目录需要满足特定的格式,举个例子,更加详细的样例代码见 https://gist.github.com/fchollet/0830affa1f7f19fd47b06d4cf89ed44d :
1 | data/ |
文本数据预处理
前言
keras提供的数据预处理总共有三种类型,他们分别用于处理图片数据、时间序列数据、文本数据,这一次要解析的就是文本数据地预处理,这些api将原始数据按照灵活的格式读入,输出指定格式的可直接输入到模型中的数据。用于处理时间序列数据的有两个,分别是text_dataset_from_directory``和``Tokenizer
text_dataset_from_directory function
1 | tf.keras.preprocessing.text_dataset_from_directory( directory, labels="inferred", label_mode="int", class_names=None, batch_size=32, max_length=None, shuffle=True, seed=None, validation_split=None, subset=None, follow_links=False,) |
这个函数将原始的文本数据(目前只支持.txt格式)转换成tf.data.Dataset类型。
如果你输入的directory目录结构是这样的:
1 | main_directory/...class_a/......a_text_1.txt......a_text_2.txt...class_b/......b_text_1.txt......b_text_2.txt |
1 | 那么调用text_dataset_from_directory(main_directory, labels='inferred')将会从子目录的批量文本class_a和class_b中返回一个tf.data.Dataset,其中标签0/1分别代表class_a和class_b. |
参数解释
directory:数据所在的目录。如果参数lables被设置为“inferred”,就如上述例子中一样,这个目录包含子目录,否则忽略目录结构。
labels:训练集的标签。
label_mode:标签的数据类型。
class_name:仅当labels是“inferred”时有效。这是类名称的明确列表(必须匹配子目录的名称)。用于控制类的顺序(否则使用字母数字顺序)。
batch_size:数据批次的大小,默认值32。
max_length:文本字符串最长的长度,超过这个值会被截断。
shuffle:是否将生成的序列数据打乱顺序
seed:随机种子,只有使用shuffle时才用
valiation_split:0-1之间的浮点数,保留用于验证的数据片段。
subset:“training”或“valiation”之一。表示valiation_split后的子集将被作为何种用途。
follow_links:是否访问符号链接指向的子目录。
Tokenizer class
1 | tf.keras.preprocessing.text.Tokenizer( num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=" ", char_level=False, oov_token=None, document_count=0, **kwargs) |
这个类允许对文本语料进行向量化,方法是将每个文本转换为一个整数序列(每个整数是字典中一个token的索引),或者转换为一个矢量。
参数解释
num_words:基于单词频率的保留单词的最大数量。只保留最常见的(num_word -1)个词。 filters:一个字符串,其中每个元素是将从文本中过滤掉的字符。默认是所有的标点符号,加上制表符和换行符,减去'字符。 lower:是否将文本转换为小写字母。 split:分词的分隔符。 char_level:如果为真,每个字符将被视为一个标记。 oov_token:如果给定,它将被添加到word_index中,用于替换text_to_sequence调用期间词汇表之外的单词
默认情况下,所有的标点符号都被删除,文本变成由空格分隔的单词组成的序列(单词可能包括“字符”)。然后这些序列被分割成记号列表。然后它们将被索引或向量化。
优化器(一)
前言
从这篇文章开始,分析神经网络的优化器以及其在keras框架中的实现。在前面讲过,神经网络的编写分成:准备数据、搭建网络结构、配置算法参数这几步,其中配置算法参数是关键的一步,而optimizer的配置是其中的重中之重。 神经网络的本质目的就是寻找合适的参数,使得损失函数的值尽可能小,该过程为称为最优化。解决这个问题的算法称为优化器。
理论模型
梯度下降法更新参数是常用的手段,举一个很简单的例子作为说明。
- 现有三组训练数据\((x,\hat{y})\)如下:
1 | (0,1) |
构建神经网络为 \(y = ax + b\)
计算损失函数 \(loss(L) = \frac{1}{2}\sum(y - \hat{y})^2 = \frac{1}{2}\sum(ax + b - \hat{y})^2 = \frac{1}{2}(b - 1)^2 + \frac{1}{2}(a + b - 2)^2 + \frac{1}{2}(2a+b-3)^2\)
计算偏导数(梯度)
- \(\frac{\partial{L} }{\partial{a} } = \sum x(ax + b - \hat{y})\)
- \(\frac{\partial{L} }{\partial{b} } = \sum (ax + b - \hat{y})\)
更新参数
- \(a \gets a - \alpha * \frac{\partial{L} }{\partial{a} }\)
- \(b \gets b - \alpha * \frac{\partial{L} }{\partial{b} }\)
\(a,b\)初始化为2,运行结果如下所示:
1 | 1.2 1.4 |
source code:
1 | global a,b,alpha |
keras接口
基本optimizer
在调用compile函数时,在函数的参数中给定优化器,可以通过实例化的方法,也可以通过字符串声明。
1 | # 实例化 |
1 | # 字符串声明 |
自定义层
在新版本的keras中可以调用apply_gradients()函数,通过将gradients,model作为传入参数更新参数,官网给出的代码如下所示。
1 | optimizer = tf.keras.optimizers.Adam() |
Learning rate decay / scheduling
通过这个接口,可以设定学习率随着时间变化,不过回调函数也可以做到这一点,后面会分析。
结尾
keras提供了8种具体的优化器,下面的几篇关于keras文章会对其进行讲解。
优化器(二)
各位读者朋友大家好,昨天我们已经了解了什么是优化器以及优化器的作用,今天我们就来看看其中的SGD和RMSprop优化器。
SGD类
1 | tf.keras.optimizers.SGD( |
随机梯度下降(Stochastic gradient descent)算法每次从训练集中随机选择一个样本来进行学习,公式如下。
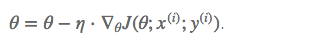
批量梯度下降算法(BGD)每次都会使用全部训练样本,因此这些计算是冗余的,因为每次都使用完全相同的样本集。而随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
随机梯度下降代码如下
1 | for i in range(nb_epochs): |
随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动),如下图:
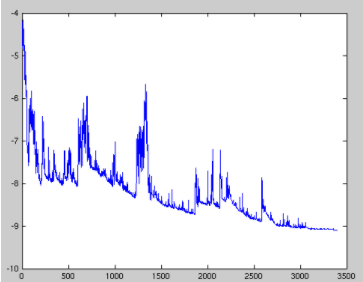
随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况,那么可能只用其中部分的样本,就已经将theta迭代到最优解了。缺点是SGD的噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。所以虽然训练速度快,但是准确度下降,并不是全局最优。虽然包含一定的随机性,但是从期望上来看,它是等于正确的导数的。
不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。
例子:
1 | opt = tf.keras.optimizers.SGD(learning_rate=0.1) |
RMSprop类
1 | tf.keras.optimizers.RMSprop( |
建议使用优化器的默认参数 (除了学习率 lr,它可以被自由调节)
这个优化器通常是训练循环神经网络RNN的不错选择。
RMSProp算法的全称叫 Root Mean Square Prop,是Geoffrey E. Hinton在Coursera课程中提出的一种优化算法。所谓的摆动幅度就是在优化中经过更新之后参数的变化范围,如下图所示,绿色的为RMSProp优化算法所走的路线。

为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重 W 和偏置 bb的梯度使用了微分平方加权平均数。 其中,假设在第 t 轮迭代过程中,各个公式如下所示:
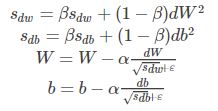
算法的主要思想就用上面的公式表达完毕了。在上面的公式中sdw和sdb分别是损失函数在前t−1轮迭代过程中累积的梯度梯度动量,ββ 是梯度累积的一个指数。所不同的是,RMSProp算法对梯度计算了微分平方加权平均数。这种做法有利于消除了摆动幅度大的方向,用来修正摆动幅度,使得各个维度的摆动幅度都较小。另一方面也使得网络函数收敛更快。(比如当 dW或者 db中有一个值比较大的时候,那么我们在更新权重或者偏置的时候除以它之前累积的梯度的平方根,这样就可以使得更新幅度变小)。为了防止分母为零,使用了一个很小的数值 ϵ来进行平滑,一般取值为10−8。
例子:
1 | opt = tf.keras.optimizers.RMSprop(learning_rate=0.1) |
今天我们学习了优化器中的SGD和RMSprop类,优化器对于神经网络来说非常重要,不同的优化方式有不同的效果,应该针对样本进行选择,以实现更好的优化效果,下周我们将继续介绍剩下的优化器,希望大家在学习之余也多多查阅相关资料,更加牢固地掌握这一知识。谢谢大家的阅读。
优化器(三)
各位读者朋友大家好,上周我们已经学习了一部分Keras的优化器,这周我们将完成优化器剩余部分的学习。
今天我们将学习几种自适应学习率优化算法。自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率,极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
Adam类
1 | tf.keras.optimizers.Adam( |
实现Adam算法的优化器。
Adam优化是一种基于随机估计的一阶和二阶矩的随机梯度下降方法。该方法计算效率高,内存需求少,不影响梯度的对角线重缩放,并且非常适合数据/参数较大的问题。
Adam中动量直接并入了梯度一阶矩(指数加权)的估计。相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。
Adam算法策略可以表示为:
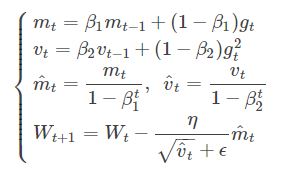
其中,mt和vt分别为一阶动量项和二阶动量项。β1,β2为动力值大小通常分别取0.9和0.999;mt,vt分别为各自的修正值。Wt表示t时刻即第t迭代模型的参数,gt=ΔJ(Wt)表示t次迭代代价函数关于W的梯度大小;ϵ是一个取值很小的数(一般为1e-8)为了避免分母为0。
例子:
1 | opt = tf.keras.optimizers.Adam(learning_rate=0.1) |
Adagrad类
1 | tf.keras.optimizers.Adagrad( |
实现Adagrad算法的优化器。
AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。
AdaGrad算法优化策略一般可以表示为:
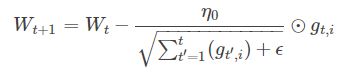
假定一个多分类问题,i表示第i个分类,t表示第t迭代同时也表示分类ii累计出现的次数。η0表示初始的学习率取值一般为0.01,ϵ是一个取值很小的数(一般为1e-8)为了避免分母为0。Wt表示t时刻即第t迭代模型的参数,gt,i=ΔJ(Wt,i)表示t时刻,指定分类i,代价函数J(⋅)关于W的梯度。
从表达式可以看出,对出现比较多的类别数据,Adagrad给予越来越小的学习率,而对于比较少的类别数据,会给予较大的学习率。因此Adagrad适用于数据稀疏或者分布不平衡的数据集。
Adagrad 的主要优势在于不需要人为的调节学习率,它可以自动调节;缺点在于,随着迭代次数增多,学习率会越来越小,最终会趋近于0。
Adadelta类
1 | tf.keras.optimizers.Adadelta( |
实现Adadelta算法的优化器。
Adadelta优化是一种随机梯度下降方法,它基于每个维度的自适应学习率来解决两个缺点:
- 整个训练期间学习率的持续下降
- 需要手动选择的整体学习率
Adadelta是Adagrad的更强大的扩展,它基于梯度更新的移动窗口来调整学习率,而不是累积所有过去的梯度。这样,即使已完成许多更新,Adadelta仍可继续学习。在此版本中,它可以像大多数其他Keras优化器一样设置初始学习率。
AdaGrad算法和RMSProp算法都需要指定全局学习率,Adadelta算法结合两种算法每次参数的更新步长。它的算法策略可以表示为:
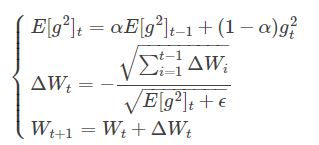
其中Wt为第t次迭代的模型参数,gt=ΔJ(Wt)为代价函数关于W的梯度。E[g2]t表示前t次的梯度平方的均值。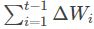 表示前t−1次模型参数每次的更新步长累加求根。
表示前t−1次模型参数每次的更新步长累加求根。
Adadelta优势在于在模型训练的初期和中期,Adadelta表现很好,加速效果不错,训练速度快。缺点在模型训练的后期,模型会反复地在局部最小值附近抖动。
优化器对于神经网络来说非常重要,不同的优化方式有不同的效果,应该针对样本进行选择,以实现更好的优化效果,希望大家在学习之余也多多查阅相关资料,更加牢固地掌握这一知识。谢谢大家的阅读。
优化器(四)
写在开篇
各位读者朋友大家好,昨天我们已经学习了一部分Keras的优化器,今天我们将完成优化器剩余部分的学习。
自适应学习率优化算法针对于机器学习模型的学习率,然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
类型说明
Adamax类
1 | tf.keras.optimizers.Adamax( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, name="Adamax", **kwargs) |
它是Adam算法基于无穷范数(infinity norm)的变种。默认参数遵循论文中提供的值。
参数w随着梯度g更新的更新规则如下:
1 | t += 1 |
伪代码:

参数
- learning_rate: 学习率。
- beta_1: 第1阶矩估计的指数衰减率。
- beta_2: 指数加权无穷范数的指数衰减率。
- epsilon: float >= 0. 模糊因子. 若为
None, 默认为K.epsilon()。与“Adam”类似,加入的epsilon是为了数值稳定性。 - name: 应用梯度时创建的操作的可选名称。默认为“Adamax”。
- **kwargs: 关键字参数。允许是'"clipnorm" 或 "clipvalue" 。"clipnorm" 按照norm裁剪梯度值;"clipvalue"按照value裁剪梯度的值。
Nadam类
1 | tf.keras.optimizers.Nadam( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, name="Nadam", **kwargs) |
Adam本质上像是带有动量项的RMSprop,Nadam就是带有Nesterov 动量的Adam RMSprop.
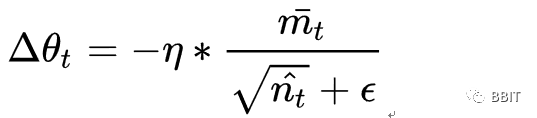
其中默认参数来自于论文,推荐不要对默认参数进行更改。
可以看出,Nadam对学习率有了更强的约束,同时对梯度的更新也有更直接的影响。一般而言,在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果。
Ftrl类
1 | tf.keras.optimizers.Ftrl( learning_rate=0.001, learning_rate_power=-0.5, initial_accumulator_value=0.1, l1_regularization_strength=0.0, l2_regularization_strength=0.0, name="Ftrl", l2_shrinkage_regularization_strength=0.0, **kwargs) |
FTRL(Follow-the-regularized-Leader)优化器
实验证明,L1-FOBOS这一类基于梯度下降的方法有较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。FTRL综合考虑了FOBOS和RDA对于正则项和W的限制,从而结合了二者的优点。
Arguments
- learning_rate_power: 控制在训练期间学习率的降低。如果想用固定的学习速率,请置为0。
- initial_accumulator_value: accumulators的初始值。
- l2_shrinkage_regularization_strength: 这个L2收缩是一个量值惩罚。当输入是稀疏的时候,收缩只会发生在活跃的权重上。
Ftrl在处理诸如逻辑回归之类的带非光滑正则化项(例如1范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色。
写在文末
优化器对于神经网络来说非常重要,不同的优化方式有不同的效果,应该针对样本进行选择,以实现更好的优化效果,希望大家在学习之余也多多查阅相关资料,更加牢固地掌握这一知识。谢谢大家的阅读。
回调函数(一)
前言
回调函数是在训练阶段可以执行各种活动的对象,训练阶段比如:每一个\(epoch\)的开头或者结尾,每一个\(batch\)之前或者之后等。接下来的讲解顺序大致就是:API的调用方法,十一个API的分析,以及自定义回调函数的例子。
使用回调函数,我们可以做到一下几件事情:
- 每几个\(batch\)之后,将\(metrics\)信息输出到日志文件中从而对训练过程进行监控
- 定期将当前的模型保存到磁盘中
- 执行\(early\ stopping\)
- 训练期间查看模型的内部状态和统计信息
- \(\dots\ \dots\)
API调用方法
一般是在\(fit()\)函数中调用,使用函数的\(callbacks\)参数进行传递,可以传递一个回调函数的对象,也可以是一个回调函数的列表,一个简单的例子如下所示,具体的每个回调函数都会在之后讲解。
1 | my_callbacks = [ |
API
Base Callback class
所有回调函数的抽象基类,如果是自定义的话,应该继承这个类,但是在API中没有直接的用处。该类有两个参数,一个是\(params\),包含了\(batch size,\ number\ of\ epochs\)等,另一个是\(model\)。
1 | tf.keras.callbacks.Callback() |
Model Checkpoint
以一定的频率保存模型或者模型的参数,这些信息将会被保存在一个\(check\ point\)文件中。被保存的模型后面可以被读取出来,继续进行训练。
更加具体的,如下所示:
- 是否只保存到目前为止性能最好的一组参数,或者忽视性能,每个\(epoch\)结束的时候都保存一下
- 在上一个功能中涉及到“性能最好”这一说法,因此就要对这个“最好”,进行定义,可以选择一个指标的最大或者最小作为最好
- 指定保存的频率,目前支持的频率为每个\(epoch\)结束之后或者在固定的训练批次之后进行保存
- 指定只保存模型的参数或者整个模型都保存下来
1 | tf.keras.callbacks.ModelCheckpoint( |
各个参数的含义如下所示:
\(filepath\):模型存储的路径,同时可以包含一些格式化选项,比如\(weights.{epoch:02d}-{val_loss:.2f}.hdf5\),对于这样的一个路径名,\(02d,.2f\)将会被替换为相应的指标值
\(monitor\):监控指标,决定了”最好“
\(verbose\):设置运行时输出信息的详细程度,0或者1
\(save\_best\_only\):布尔变量,如果设置为真,则最终结果中只保存效果最好的一组参数
\(mode\):字符串,\(auto,min,max\)中的一个,如果是监控的指标是正确率的话,一般是最大,损失函数的话一般是最小化,不过这个一般用\(auto\),程序可以自己判断
\(save\_weights\_only\):布尔变量,字面意思
\(save\_freq\):\('epoch'\)或者一个整数,前者对应每个\(epoch\)保存一次,后者对应若干个\(batch\)之后保存
在这里给出一个简单的例子
1 | EPOCHS = 10 |
Tensor Board
对训练过程中的数据或者结果进行可视化,具体的如下所示:
- 指标摘要图
- 训练图可视化
- 激活直方图
- 采样分析
关于tensorboard,在后面会进行更加详细的分析。
Early Stopping
当某个指标已经停止优化时,不过这里用到的指标必须是调用compile函数时必须包含的指标,对于一些没有默认包含的指标,一定要用metrics参数指明。
1 | tf.keras.callbacks.EarlyStopping( |
- \(monitor\):监控的指标
- \(min\_delta\):认为在某一指标上提升多少才算一次优化
- \(patience\):连续多少次没有优化之后就停止
- \(verbose\):同上
- \(mode\):同上
- \(baseline\):阈值,如果结果没有达到这个值,即使\(patience\)到了也不停
- \(restore\_best\_weights\):是否保存最优结果,与上面的功能有些重叠
Learning Rate Scheduler
可以在训练的过程中使用变化的学习率
1 | tf.keras.callbacks.LearningRateScheduler(schedule, verbose=0) |
这里的第一个参数是一个函数,函数的传入参数是\(epoch,lr\),其中\(epoch\)是当前的训练轮数,\(lr\)是当前的学习率,返回一个新的学习率,可以自定义函数,根据当前的状况,决定学习率,如果想要实现一个根据loss的变化确定的学习率,也可以设置一个全局变量来解决这个问题。
1 | def scheduler(epoch, lr): |
回调函数(二)| tensorboard函数
回调函数 tensorboard
机器学习过程中可视化的有力工具,在keras中的API如下所示:
1 | tf.keras.callbacks.TensorBoard( |
参数解释:
- \(log\_dir\):存储日志文件的路径,这些日志文件将会被tensorboard解析
- \(histogram\_freq\):模型个层的激活和权重的直方图计算的频率,单位是epoch,如果被置为0,就不进行该计算
- \(write\_graph\):是否对graph进行可视化,如果使用该选项,日志文件会变得很大
- \(write\_images\):是否可视化模型参数
- \(update\_freq\):记录指标和loss的频率,可以是\('batch','epoch'\)或者一个整数,如果是一个整数就是说若干batch记录一次,如果记录的太频繁会降低记录速度
- \(profile\_batch\):分析批次中以采样计算特征
使用方法
编写keras程序,比如一段主程序如下所示:
1 | def test_tensor(epochs = 100): |
程序运行结束之后,在文件的同目录下发现多出来一个logs文件夹,这个文件夹的绝对路径命名为\(XXX\),随后在命令行中输入如下命令行tensorboard --logdir=XXX,待tensorboard启动后,使用浏览器中的本地服务器,进入https://localhost:6006/就可以看到tensorboard处理的可视化结果了,如图所示
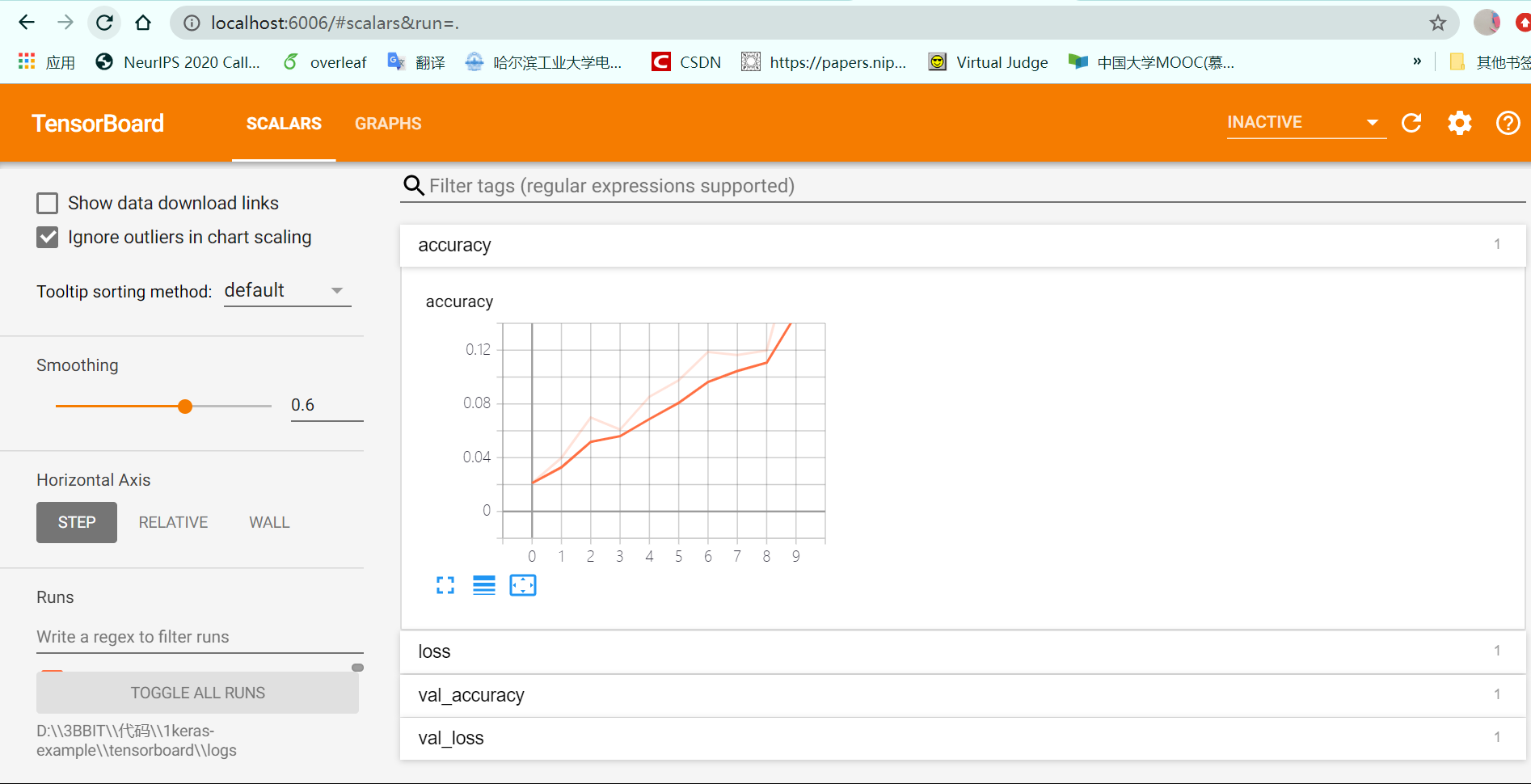
目录栏目有两个选项,scalar如下所示,展示的metrics的变化情况
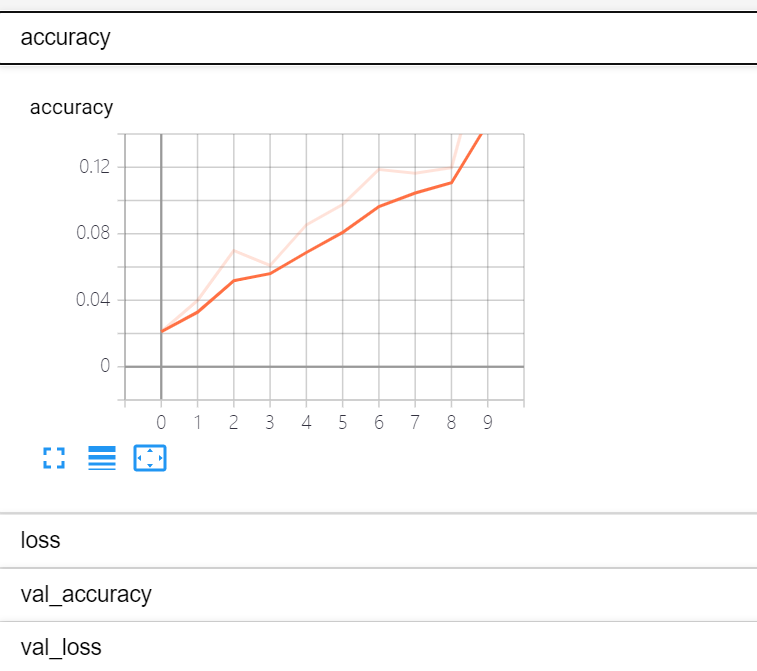
graph展示的是模型的结构,可视化如下所示:
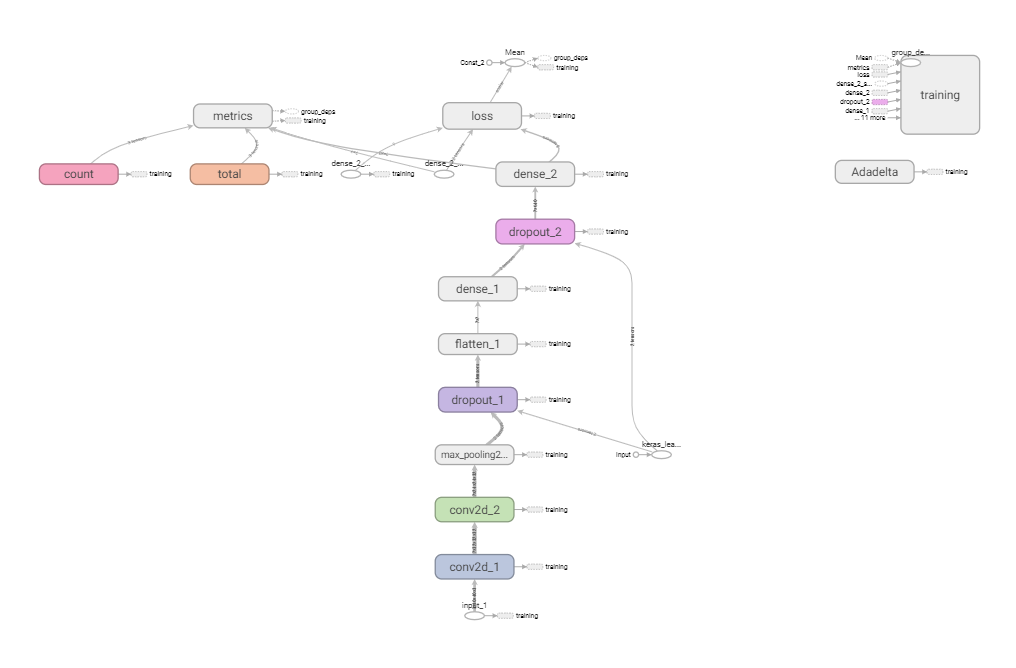
完整代码已经被上传在https://github.com/1173710224/tensorboard-usage/tree/master可以通过调整模型的参数查看具体每个参数的作用
回调函数(三)
今天我们继续来学习Keras中的回调函数剩下的部分。
ReduceLROnPlateau类
1 | tf.keras.callbacks.ReduceLROnPlateau( |
作用:
该函数用于当被监控的数据(monitor)停止提升时,降低学习率。
当数据停止提升时,模型总是会受益于降低2-10倍的学习率。这个回调函数监测一个数据并当这个数据在参数"patience"规定的轮数之后还没有提升的话,那么学习率就会被降低。
例子:
1 | reduce_lr = ReduceLROnPlateau(monitor='val_loss',factor=0.2,patience=5, min_lr=0.001) |
RemoteMonitor类
1 | tf.keras.callbacks.RemoteMonitor( |
作用:
可以将事件数据流式处理到服务器。
需要request库。事件被默认发送到 root + '/publish/epoch/end/'。 采用 HTTP POST ,其中的 data 参数是以 JSON 编码的事件数据字典。 如果 send_as_json 设置为 True,请求的 content type 是 application/json。否则,将在表单中发送序列化的 JSON。
LambdaCallback类
1 | tf.keras.callbacks.LambdaCallback( |
作用:
可以在训练进行中创建简单的自定义回调函数。
这个回调函数在规定的时间被创建。需要注意的是回调函数要求位置型参数,如下:
on_epoch_begin 和 on_epoch_end 要求两个位置型的参数: epoch, logs
on_batch_begin 和 on_batch_end 要求两个位置型的参数: batch, logs
on_train_begin 和 on_train_end 要求一个位置型的参数: logs
例子:
1 | #在每批次前打印批序号 |
TerminateOnNaN类
1 | tf.keras.callbacks.TerminateOnNaN() |
作用:
在遇到一个NaN loss时终止训练。
CSVLogger类
1 | tf.keras.callbacks.CSVLogger( |
作用:
把训练轮结果数据流式处理到csv文件。
支持所有可以被作为字符串表示的值,包括 1D 可迭代数据,例如,np.ndarray。
例子:
1 | csv_logger = CSVLogger('training.log') |
ProgbarLogger类
1 | tf.keras.callbacks.ProgbarLogger( |
作用:
会把评估以标准输出进行打印
注意:
ValueError:如果采用无效的count_mode会报错
回调函数是一个函数的合集,它在训练的各个阶段都可以使用,使用好回调函数可以让人对网络训练的情况有更直观的了解,并且可以对训练过程进行调整优化,作用很大。所以希望大家能够在实际案例中进行尝试,使自己更深刻地掌握回调函数的用法。谢谢大家观看!
回调函数(四)|自定义回调函数
上周我们整体介绍了回调函数API,今天我们就来讲讲如何编写你自己的回调函数。
所有的回调函数都是keras.callbacks.Callback类的子类,并且覆盖在训练和预测的各个阶段。回调函数对于在训练期间了解模型的内部状态和统计信息很有用。
自定义回调函数方法概述
可以把回调列表(作为关键字参数callbacks)传递给以下模型方法以使用回调函数:
keras.Model.fit()keras.Model.evaluate()keras.Model.predict()
全局方法:
on_(train|test|predict)_begin(self, logs=None):在fit/evaluate/predict的开头调用该回调函数。
on_(train|test|predict)_end(self, logs=None):在fit/evaluate/predict结束时调用该回调函数。
批次级方法:
on_(train|test|predict)_batch_begin(self, batch, logs=None):在training/testing/predicting期间处理批次之前调用该回调函数。
on_(train|test|predict)_batch_end(self, batch, logs=None):在training/testing/predicting期间处理批次结束时调用该回调函数。
epoch级方法(仅在train阶段):
on_epoch_begin(self, epoch, logs=None):在train期间的开始时调用。
on_epoch_end(self, epoch, logs=None):在train期间的结束时调用。
例子:
1 | #编写该回调函数,使用所有的方法,观察各方法的执行位置 |
1 | #执行结果 |
logs字典的用法
logs字典包含loss值,以及批处理或epoch结束时的所有度量。例如包括loss和平均绝对误差。
例子:
1 | class LossAndErrorPrintingCallback(keras.callbacks.Callback): |
1 | #执行训练结果 |
self.model的用法
除了在调用其中一种方法时接收日志信息外,回调还可以访问与当前一轮fit/evaluate/predict相关联的模型self.model。以下是self.model可以在回调中执行的操作:
- 设置
self.model.stop_training = True为立即中断训练。 - 修改优化程序的超参数(可通过获取
self.model.optimizer),例如self.model.optimizer.learning_rate。 - 定期保存模型。
model.predict()在每个时期结束时记录一些测试样本的输出,以在训练期间用作健全性检查。- 在每个时期结束时提取中间特征的可视化,以监视模型随时间推移正在学习的内容。
例子:
1 | #该回调函数在达到最小损失时停止训练 |
相信大家经过今天的学习,对于回调函数会有更深刻的理解,大家需要多多动手尝试,构建自己的回调函数,以加深印象,达到更好的学习效果。谢谢大家观看!
回归损失函数(一)
开篇
这次要与大家分享的是回归损失函数,常见的损失函数有\(mse,me,mae\)等。我们在这里整理了keras官方给出的不同的loss函数的API,并从网上搜集了相关函数的一些特性,把他们整理在了一起。这部分的loss按照keras官方的教程分成class和function两部分,这一次讲的是class部分。
API
MeanSquaredError(mse)
$loss = $
计算的是标签和预测值的误差的平方的平均值,俗称均方误差。
1 | y_true = [[0., 1.], [0., 0.]] |
数理统计中均方误差是指参数估计值与参数值之差平方的期望值,记为MSE。MSE是衡量“平均误差”的一种较方便的方法,MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
在compile时的用法如下所示:
1 | model.compile(optimizer='sgd', loss=tf.keras.losses.MeanSquaredError()) |
缺点
假设我们使用的激活函数为sigmod\(\sigma()\),则在训练过程中存在如下问题:
设\(loss = J = \frac{1}{2}(y_i - \hat{y}_i)^2\)
求反向传播所需梯度为 \(\frac{\partial J}{\partial W} = (y_i - \hat{y}_i)\sigma'(Wx_i+b)x_i\)
而 \[ \sigma'(\Delta) = (\frac{1}{1 + e^{-\Delta} })'\\ = (\frac{1}{1 + e^{-\Delta} })^2 - \frac{1}{1 + e^{-\Delta} }\\ = (\sigma(\Delta))^2 - \sigma(\Delta)\\ = \sigma(\Delta)(\sigma(\Delta) - 1)\\ \] 所以如果预测结果是很接近0或者1的,会导致梯度非常的小,从而训练速度也会很低。
一种解决办法是使用交叉熵作为损失函数,这在后面会讲到。
MeanAbsoluteError(mae)
\(loss = \frac{\sum|y_{true} - y_{pred}|}{n}\)
计算差的绝对值的均值, 可以更好地反映预测值误差的实际情况。
俗称平均绝对值误差,也称L1损失。上面的mse时L2损失。
1 | model.compile(optimizer='sgd', loss=tf.keras.losses.MeanAbsoluteError()) |
MeanAbsolutePercentageError(mape)
\(loss = \frac{\sum100*\frac{|y_{true} - y_{pred}|}{y_{true} } }{n}\)
这个公式更能表示预测值与标签的相对关系,乘以100的目的是为了放大loss函数。
1 | model.compile(optimizer='sgd', |
MeanSquaredLogarithmicError(msle)
$loss = $
从形式上看是把每一项的loss缩小了,是mse的一个修改版本,这样做有什么好处呢?请看下面这个例子(引自 https://blog.csdn.net/leadai/article/details/78876511 )。
\(y_{true}\):[1,2,3,100] \(y_1\):[1,2,3,110] \(y_2\):[2,3,4,100]
可以计算一下如果是mse的话,\(y_2\)会成为更优的预测结果,如果用msle,则是\(y_1\),在这里显然\(y_1\)更优。
1 | model.compile(optimizer='sgd', |
CosineSimilarity
\(loss = -\sum(l2\_norm(y_{true}) * l2\_norm(y_{pred}))\)
请注意,它是介于-1和0之间的负数,其中0表示正交,而接近-1的值表示更大的相似性。 这使得它在尝试最大化预测值与目标值之间的接近度的设置中可用作损失函数。 如果y_true或y_pred是零向量,则余弦相似度将为0,而与预测值和目标值之间的接近程度无关。
从形式上看,是向量的点乘,从抽象的角度来看,是两个向量之间夹角的衡量,当两个向量正交时是不希望的情况,对应的cosine是0,损失函数的结果也是0,当两个向量夹角为零,cosine为1,正则化的计算结果也是1。最后在公式前面乘以-1,统一化成最小化计算。
1 | model.compile(optimizer='sgd', loss=tf.keras.losses.CosineSimilarity(axis=1)) |
回归损失函数(二)
前言
在regression loss(1)中简单介绍了一些关于回归loss函数、相应的性质以及其在keras下的类实现,也就是在调用compile时的使用方法,这一次来简单看一下keras针对此定义的一些loss函数实现、相应的输入输出的shape以及一些编程的细节问题。
实现
以 mean_squared_error 为例
1 | tf.keras.losses.mean_squared_error(y_true, y_pred) |
一个关于使用该函数的例子如下所示(可运行):
1 | import numpy as np |
输出为
1 | (2, 3) |
其中输入的两个变量的shape是\((batch\_size,d_0, .. d_N)\),输出的loss的shape是\((batch\_size,d_0, .. d_{N-1})\)
借另外一个例子看一下这个过程
1 | (2, 3, 4) |
第三个维度上的向量长度是4,在\(y\_true\)和\(y\_pred\)对应位置的向量会被一次处理,比如上面这个例子中的\([1\ 0\ 1\ 1]\)和\([0.02513952\ 0.9691113\ 0.06320494\ 0.20428369]\)会调用\(mse\)被处理成一个值。于是最后计算出来的loss就少一个维度了。
其它的
其余类似,总结一下,如下所示:
1 | tf.keras.losses.mean_absolute_error(y_true, y_pred) |
huber class
首先定义\(x \gets y\_true - y\_pred\)
于是loss就如下计算
1 | loss = 0.5 * x^2 if |x| <= d |
一个简单的例子如下所示:
1 | y_true = [[0, 1], [0, 0]] |
在进行编译时的例子:
1 | model.compile(optimizer='sgd', loss=tf.keras.losses.Huber()) |
对于这个loss函数的理解非常简单:当预测值和真实值相差很小的时候就用平方损失函数,否则通过一定的手段降低loss。
概率损失函数篇
上周,我们一起学习了概率loss和回归loss中的class,今天我们便要完成接下来的内容:概率loss的function部分。
binary_crossentropy 函数
1 | tf.keras.losses.binary_crossentropy( |
作用:
计算二分类任务交叉熵损失。
二分类任务交叉熵损失函数如下所示:

二分类对应的神经网络的最后一层为sigmoid。
例子:
1 | y_true = [[0, 1], [0, 0]] |
最终返回二分类任务交叉熵损失值,形如[batch_size, d0, .. dN-1]
categorical_crossentropy 函数
1 | tf.keras.losses.categorical_crossentropy( |
作用:
计算多分类任务交叉熵损失。
多分类任务交叉熵损失函数如下所示:
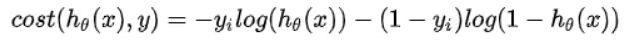
多分类对应的神经网络的最后一层为softmax。
例子:
1 | y_true = [[0, 1, 0], [0, 0, 1]] |
最终返回多分类任务交叉熵损失值。
sparsecategorical_crossentropy 函数
1 | tf.keras.losses.sparse_categorical_crossentropy( |
作用:
计算稀疏多分类任务交叉熵损失。
例子:
1 | y_true = [1, 2] |
最终返回稀疏多分类任务交叉熵损失值。
poisson函数
1 | tf.keras.losses.poisson( |
作用:
计算标签值和预测值之间的泊松loss。
泊松损失是张量y_pred - y_true * log(y_pred)元素的平均值。
例子:
1 | y_true = np.random.randint(0, 2, size=(2, 3)) |
最终返回泊松损失值,形如[batch_size, d0, .. dN-1]。
当y_true和y_pred有不兼容的形状时报错:InvalidArgumentError
kl_divergence函数
1 | tf.keras.losses.kl_divergence( |
作用:
计算标签值和预测值之间的Kullback-Leibler散度loss。
loss的计算公式为:loss = y_true * log(y_true / y_pred)。
例子:
1 | y_true = np.random.randint(0, 2, size=(2, 3)).astype(np.float64) |
最终返回Kullback-Leibler散度损失值。
如果y_true不能被转换为y_pred的类型时报错:TypeError
损失函数对于神经网络的训练极其重要,一个适当的损失函数可以大大加快神经网络的训练速度,以及帮助神经网络找到最优解。所以如果想要科学构建神经网络,一定要将损失函数了解透彻,希望大家下去多多查阅相关资料,巩固知识。谢谢大家耐心观看!
数据集(一)
前言
keras提供了几个数据集,可以通过\(load\_data\)函数直接调用,具体如下所示
mnist digits 分类数据集
这是一个包含0,1,2,3,4,5,6,7,8,9的60,000张28x28灰度图像的数据集,以及10,000张图像的测试集。
1 | tf.keras.datasets.mnist.load_data(path="mnist.npz") |
其中\(path\)参数指定了数据集在本地缓存的位置,函数的返回值是两个numpy类型的数组,\((x\_train, y\_train), (x\_test, y\_test)\)。其中,\((x\_train, y\_train)\)是数据,shape是\((num\_samples,28,28)\),\((x\_test, y\_test)\)是标签,shape是\((num\_samples,)\)。这里得到的仅仅是矩阵数据,如果想要看到这个图片,还需要进一步的可视化操作。
CIFAR10 小图片分类数据集
这是50,000个32x32色彩训练图像和10,000个测试图像的数据集,标记了10个类别。
1 | tf.keras.datasets.cifar10.load_data() |
这里不支持本地cache,返回值的类型和mnist是一样的,但是数组\((x\_train, y\_train)\)的shape有所区别,\((num\_samples, 3, 32, 32)\),由于是彩色的,使用的是RGB色彩标准,所以是三个通道,相对于mnist就稍微复杂了一些
CIFAR100 小图片分类数据集
这是一个50,000个32x32彩色训练图像和10,000个测试图像的数据集,标记了100多个细粒度的类别,这些细类被分组为20个粗粒度的类别。
1 | tf.keras.datasets.cifar100.load_data(label_mode="fine") |
由于数据集有两种不同粒度的标签,在调用数据集时应该指明数据集的标签是哪一个,这个信息是通过\(label\_mode\)这个参数传递的,当参数的值为fine时,分为100个类别,当参数值为coarse时,分为10个类别。函数的返回值和cifar10一摸一样。
IMDB 电影评论数据集
这是来自IMDB的25,000条电影评论的数据集,并按情感(正/负)进行标记。 评论已经过预处理,并且每个评论都被编码为单词索引(整数)列表。 为了方便起见,单词以数据集中的整体频率索引,因此,例如整数“ 3”编码数据中第3个最频繁出现的单词。 这样就可以进行快速过滤操作,例如:“仅考虑前10,000个最常用的词,而排除前20个最常用的词”。
按照惯例,“ 0”不代表特定单词,而是用于编码任何未知单词。
1 | tf.keras.datasets.imdb.load_data( |
参数解释
num_words:所有的单词都按照词频进行排序了,如果改参数是一个整数,那么训练集中就只包含词频最高的num_words单词,剩余的单词都会被oov_char代替,否则就是所有的单词。
skip_top:输出训练集的时候跳过词频最高的几个单词,并使用oov_char代替。
maxlen:整数或者空值,表示限制训练集合中的句子序列的最大长度
seed:随机种子,打乱数据集时使用
start_char:给每个序列的开始处标记一个字符,是一个整数,一般可以用1
oov_char:上面提到过了,相当于是一个统一填充值
函数的返回值依然是 \((x\_train, y\_train), (x\_test, y\_test)\)
另一个接口是tf.keras.datasets.imdb.get_word_index(path="imdb_word_index.json"),这个函数用于获取单词和index之间的映射关系,返回值是键值类型的,键是单词字符串,值是单词对应的索引。
数据集(二)
今天我们来继续说明Keras剩下的三个内置数据集。
路透社新闻分类数据集
数据集来源于路透社的 11,228 条新闻文本,总共分为 46 个主题。
load_data功能
1 | tf.keras.datasets.reuters.load_data( |
该功能用于加载路透社新闻分类数据集,这最初是通过解析和预处理经典的Reuters-21578数据集生成的,但是预处理代码不再与Keras打包在一起。
与 IMDB 数据集一样,每条新闻都被编码为一个词索引的序列(相同的约定)。为了方便起见,单词以数据集中的整体频率索引,因此,例如整数“ 3”编码数据中第3个最频繁出现的单词。这样就可以进行快速过滤操作,例如:“仅考虑前10,000个最常用的词,而排除前20个最常用的词”。
按照惯例,“ 0”不代表特定单词,而是用于编码任何未知单词。
返回值:
Numpy数组的元组:(x_train, y_train), (x_test, y_test)。
x_train,x_test:序列列表,它是索引(整数)列表。如果num_words参数是特定的,则最大可能的索引值为num_words - 1。如果maxlen指定了参数,则最大可能的序列长度为maxlen。
y_train,y_test:整数标签(1或0)的列表。
get_word_index功能
1 | tf.keras.datasets.reuters.get_word_index( |
检索将单词映射到路透数据集中索引的字典。
返回值:
单词索引字典。键是单词字符串,值是它们的索引。
Fashion-MNIST时尚物品数据集
这是一个包含10个时尚类别的60,000张28x28灰度图像的数据集,以及10,000张图像的测试集。该数据集可以用作MNIST的替代品。类标签是:
| 标签 | 描述 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 拉过来 |
| 3 | 连衣裙 |
| 4 | 涂层 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 袋 |
| 9 | 脚踝靴 |
load_data功能
1 | tf.keras.datasets.fashion_mnist.load_data() |
加载Fashion-MNIST数据集。
返回值:
Numpy数组的元组:(x_train, y_train), (x_test, y_test)。
x_train,x_test:uint8个形状为(num_samples,28,28)的灰度图像数据数组。
y_train,y_test:uint8个形状为(num_samples,)的标签数组(范围为0-9的整数)。
Boston房价回归数据集
数据集来自卡内基梅隆大学维护的 StatLib 库。
样本包含 1970 年代的在波士顿郊区不同位置的房屋信息,总共有 13 种房屋属性。 目标值是一个位置的房屋的中值(单位:k$)。
load_data功能
1 | tf.keras.datasets.boston_housing.load_data( |
加载波士顿房屋数据集。
返回值:
Numpy数组的元组:(x_train, y_train), (x_test, y_test)。
x_train,x_test:具有(num_samples, 13) 包含训练样本(对于x_train)或测试样本(对于y_train)的形状的numpy数组。
y_train,y_test:(num_samples,)包含目标标量的numpy形状数组。目标是通常在10到50之间的浮动标量,以k $表示房价。
谢谢大家的观看!
工具
CustomObjectScope class
1 | tf.keras.utils.custom_object_scope(*args) |
将自定义类/函数暴露给Keras反序列化内部组件。在具有custom_object_scope(objects_dict)的作用域下,诸如tf.keras.models.load_model或tf.keras.models.model_from_config之类的Keras方法将能够反序列化已保存配置引用的任何自定义对象(例如,自定义层或度量指标)。
例子
考虑一个自定义的正则化器 my_regularizer
1 | layer = Dense(3, kernel_regularizer=my_regularizer) |
其中{'my_regularizer': my_regularizer}是函数的参数,都是键值类型的。
get_custom_objects function
1 | tf.keras.utils.get_custom_objects() |
检索对自定义对象的全局词典的实时引用。首选使用custom_object_scope更新和清除自定义对象,但可以使用get_custom_objects直接访问当前的自定义对象集合。
register_keras_serializable function
1 | tf.keras.utils.register_keras_serializable(package="Custom", name=None) |
向Keras序列化框架注册对象。该修饰器将修饰后的类或函数注入Keras定制对象字典中,以便无需用户提供的定制对象字典中的条目即可对其进行序列化和反序列化。 它还注入了Keras将调用的函数,以获取对象的可序列化的字符串键。请注意,要进行序列化和反序列化,类必须实现get_config()方法。 函数没有此要求。该对象将在“ package> name”项下注册,其中名称为name,如果未通过,则默认为对象名。
下面两个虽然简单,但是是重要的函数
serialize_keras_object function
1 | tf.keras.utils.serialize_keras_object(instance) |
将Keras对象序列化为JSON兼容的表示形式。
deserialize_keras_object function
1 | tf.keras.utils.deserialize_keras_object( |
将Keras对象的序列化形式转换回实际对象。
畅游人工智能之海 | Keras教程之工具函数(一)
类型介绍
模型绘制
数据集来源于路透社的 11,228 条新闻文本,总共分为 46 个主题。
plot_model参数一览
1 | tf.keras.utils.plot_model( model, #你想绘制的keras模型实例 to_file="model.png" #想要保存的文件路径和文件名 show_shapes=False, #是否显示网络层的尺寸信息 show_dtype=False, #是否显示网络层的dtypes show_layer_names=True,#显示网络层的名字 rankdir="TB", #这个参数会传递给PyDot,用以确定图像的格式,例如‘TB’会垂直地绘制,‘LB’会水平地绘制图像 expand_nested=False, #是否将嵌套模型扩展为集群 dpi=96, #图像清晰度的参数) |
实例:
1 | input = tf.keras.Input(shape=(100,), dtype='int32', name='input')x = tf.keras.layers.Embedding( output_dim=512, input_dim=10000, input_length=100)(input)x = tf.keras.layers.LSTM(32)(x)x = tf.keras.layers.Dense(64, activation='relu')(x)x = tf.keras.layers.Dense(64, activation='relu')(x)x = tf.keras.layers.Dense(64, activation='relu')(x)output = tf.keras.layers.Dense(1, activation='sigmoid', name='output')(x)model = tf.keras.Model(inputs=[input], outputs=[output])dot_img_file = '/tmp/model_1.png'tf.keras.utils.plot_model(model, to_file=dot_img_file, show_shapes=True) |
如果运行正确,你应当在对应的tofile路径下找到绘制出的图片
返回值:
该如果安装了Jupyter,该函数就会返回一个Jupyter笔记本的图像对象。
model_to_dot
1 | tf.keras.utils.model_to_dot( model, #keras模型实例 show_shapes=False, show_dtype=False, show_layer_names=True, rankdir="TB", expand_nested=False, dpi=96, subgraph=False,#是否返回一个pydot.Cluster实例) |
把Keras模型转换成dot类型
返回值:
返回一个模型对应的pydot.Dot实例,如果subgraph设定为true,则会返回一个 pydot.Cluster实例
序列化工具
CustomObjectScope
1 | tf.keras.utils.custom_object_scope(*args) |
Keras反序列化内部公开自定义类/函数。
在custom_object_scope(objects_dict)作用域中,可以使用诸如tf.keras.modelsload_model或tf.keras.models这样的方法来反序列化被保存的配置引用的任何自定义对象(例如自定义层或指标)。
例如:
1 | layer = Dense(3, kernel_regularizer=my_regularizer)config = layer.get_config() # Config contains a reference to `my_regularizer`...# Later:with custom_object_scope({'my_regularizer': my_regularizer}): layer = Dense.from_config(config |
*args是一个字典{name:object}序列。
1 | register_keras_serializable |
`` 向Keras序列化框架注册一个对象。 这个装饰器将修饰过的类或函数注入到Keras自定义对象字典中,这样它就可以被序列化和反序列化,而不需要在用户提供的自定义对象dict中添加条目。注意,要序列化和反序列化,类必须实现get_config()方法。函数不需要此要求。
对象将在关键字“package>name”下注册,其中name,如果没有设置,则默认为对象名称。
参数:
package:这个类所属的包名
name:要在这个包下序列化这个类的名称。如果没有,则使用类的名称。
返回值:用传递的名称注册被修饰类的装饰器。
serialize_keras_object
1 | tf.keras.utils.serialize_keras_object(instance) |
将Keras对象序列化为json兼容的表示。
1 | deserialize_keras_object |
返回值:
将Keras对象的序列化形式转换回实际对象。
后端工具
今天我们要开始学习Keras的后端函数。
首先我们要了解什么是后端。Keras依赖于一个专门的、优化的张量操作库来完成一系列操作,它可以作为Keras的后端引擎。相比单独地选择一个张量库,而将Keras的实现与该库相关联,Keras以模块方式解决这个问题,它可以将几个不同的后端引擎无缝嵌入到Keras中。
目前,Keras有三个后端实现可用:TensorFlow后端、Theano后端和CNTK后端。可以通过手动操作对后端进行切换,这里不再赘述。
以下我们来学习Keras的后端函数。
clear_session函数
1 | tf.keras.backend.clear_session() |
该函数可以重置Keras生成的所有状态。
Keras管理全局状态,该状态用于实现功能模型构建API并统一自动生成的图层名称。
它可以销毁当前的TF图并创建一个新图。有利于避免旧模型/网络层混乱。
例子:
1 | # 例1:clear_session()在循环中创建模型时调用 |
floatx函数
1 | tf.keras.backend.floatx() |
该函数以字符串形式返回默认的float类型。
例如‘float16’,‘float32’,‘float64’
返回值:
String类型,当前的默认浮点类型。
例子:
1 | tf.keras.backend.floatx() |
set_floatx函数
1 | tf.keras.backend.set_floatx( |
该函数设置默认的浮点类型。
注意:建议不要将其设置为float16进行训练,因为这可能会导致数值稳定性问题。另外,可以通过调用tf.keras.mixed_precision.experimental.set_policy('mixed_float16')来混合使用float16和float32的混合精度。
例子:
1 | tf.keras.backend.floatx() |
注意:如果输入值无效时,报错:“ValueError”
image_data_format函数
1 | tf.keras.backend.image_data_format() |
返回默认的图像数据格式约定。
返回值:
String类型,‘channels_first’或者‘channels_last’
例子:
1 | tf.keras.backend.image_data_format() |
set_image_data_format函数
1 | tf.keras.backend.set_image_data_format( |
设置图像数据格式约定。
例子:
1 | tf.keras.backend.image_data_format() |
注意:如果输入值无效时,报错:“ValueError”
明天我们将继续展开对后端函数的学习,谢谢大家的观看!
epsilon function
注意使用的时候把tf改成tensorflow!
1 | tf.keras.backend.epsilon() |
返回数字表达式中使用的模糊因子的值,运行下面的程序输出的就是,这个模糊因子可以理解为当两个变量的值差的绝对值不超过这个模糊因子,就认为是相等的。
1 | import tensorflow |
set_epsilon function
1 | tf.keras.backend.set_epsilon(value) |
更改上述提到的模糊因子的值
1 | tf.keras.backend.epsilon() |
is_keras_tensor function
1 | tf.keras.backend.is_keras_tensor(x) |
判断输入中的x是不是keras张量,所谓keras张量就是由keras提供的层API的返回值
官网给出了很多例子,如下所示:
1 | np_var = np.array([1, 2]) |
get_uid function
1 | tf.keras.backend.get_uid(prefix="") |
每个建好的神经网络都对应一个计算图,这个图有一个id,通过一个与图相关的字符串可以找到这个id,关于使用方法如下所示:
1 | get_uid('dense') |
rnn function 基本没用!
1 | tf.keras.backend.rnn( |
指标函数
Metrics函数是用于判断模型性能的函数。
Metrics函数与损失函数类似,不同之处在于训练模型时不使用指标函数的结果。我们可以使用任何损失函数作为指标。
指标函数有非常多种类,如精度指标、概率指标、回归指标等等,今天我们来整体概述一下Metrics函数。
compile()中的用法
compile:
compile方法会采用一个metrics参数,该参数是Metrics的列表:
1 | model.compile( |
独立使用
与损失不同,指标是有状态的。使用update_state()方法更新其状态,并使用result()方法查询标量指标结果:
1 | m = tf.keras.metrics.AUC() |
以下是如何将指标用作简单自定义培训循环的一部分:
1 | accuracy = tf.keras.metrics.CategoricalAccuracy() |
创建自定义指标
作为简单的可调用(无状态)
与loss函数非常类似,任何具有签名metric_fn(y_true,y_pred)的可调用函数返回一个损失数组(输入批处理中的一个示例)都可以作为指标传递给compile()。请注意,对于任何此类指标,都自动支持样本权重。
下面是一个简单的例子:
1 | def my_metric_fn(y_true, y_pred): |
作为Metric的子类(有状态)
并不是所有的指标都可以通过无状态的可调用项来表示,因为在培训和评估期间,每个批次的指标值都是经过评估的,但是在某些情况下,每个批次值的平均值并不是您感兴趣的。
假设您想要计算给定评估数据集的AUC:每批AUC值的平均值与整个数据集的AUC值的平均值不同。
对于这样的度量,您将希望Metric类的子类,该类可以跨批维护状态。很简单:
在__init__中创建状态变量
更新Update_state()中给定y_true和y_pred的变量
在result()中返回度量结果
清除reset_states()中的状态
下面是一个计算二进制真正数的简单示例:
1 | class BinaryTruePositives(tf.keras.metrics.Metric): |
add_metric() API
在编写自定义层或子类模型的前向传递时,有时可能需要动态记录某些数量,作为指标。在这种情况下,可以使用add_metric()方法。
假设你想要记录一个密集的自定义层的激活的平均值。您可以执行以下操作:
1 | class DenseLike(Layer): |
然后将以“activation_mean”的名称跟踪数量。跟踪的值将是每批指标值的平均值(由aggregation='mean'指定)。
明天我们将具体地学习指标函数,谢谢大家的观看!
精度指标
类型介绍
Accuracy metrics类
1 | tf.keras.metrics.Accuracy(name="accuracy", dtype=None) |
作用:
该函数用来计算模型预测准确的频率。如果sample_weight为None,权重默认置为1.
例子:
1 | model.compile(optimizer='sgd', loss='mse', metrics=[tf.keras.metrics.Accuracy()]) |
BinaryAcuracy类
1 | tf.keras.metrics.BinaryAccuracy( name="binary_accuracy", dtype=None, threshold=0.5) |
作用:
与Accuracy metrics类相似,只不过判别预测结果与标签是否匹配是按照二分类的情形判别的。
1 | >>> m = tf.keras.metrics.BinaryAccuracy()>>> m.update_state([[1], [1], [0], [0]], [[0.98], [1], [0], [0.6]])>>> m.result().numpy()0.75 |
CategoricalAccuracy类
1 | tf.keras.metrics.CategoricalAccuracy(name="categorical_accuracy", dtype=None) |
作用:
用来计算one-hot标签的准确率
例子:
1 | >>> m.reset_states()>>> m.update_state([[0, 0, 1], [0, 1, 0]], [[0.1, 0.9, 0.8],... [0.05, 0.95, 0]],... sample_weight=[0.7, 0.3])>>> m.result().numpy()0.3 |
TopCategoricalAccuracy类
1 | tf.keras.metrics.TopKCategoricalAccuracy( k=5, name="top_k_categorical_accuracy", dtype=None) |
作用:
计算前k个的准确率,默认值k=5
1 | >>> m = tf.keras.metrics.TopKCategoricalAccuracy(k=1)>>> m.update_state([[0, 0, 1], [0, 1, 0]],... [[0.1, 0.9, 0.8], [0.05, 0.95, 0]])>>> m.result().numpy()0.5 |
SparseTopK*CategoricalAccuracy*类
1 | tf.keras.metrics.SparseTopKCategoricalAccuracy( k=5, name="sparse_top_k_categorical_accuracy", dtype=None) |
作用:
计算离散整数的topK准确率
例子:
1 | >>> m = tf.keras.metrics.SparseTopKCategoricalAccuracy(k=1)>>> m.update_state([2, 1], [[0.1, 0.9, 0.8], [0.05, 0.95, 0]])>>> m.result().numpy()0.5 #[2,1]相当于对应lable最大值的下标 |
写在文末
Accuracy metrics是对模型准确度的测量。keras提供了许多函数,来应对不同数据格式下准确率测度计量的问题。